
Revered by all from the ancients to today, and made through a cataclysmic event involving nuclear fusion of several chemical elements, gold is ranked as one of our most precious metals. In the age of technology, business critical application services are as sought after as gold. Services are more than just machine code created by smart developers; they’re made of many infrastructure elements which are forged together, including database, web servers, application delivery controllers and the like. To protect your IT gold, you need to closely monitor all of these elements to ensure service is fully available, and the only downtime is planned downtime.
There are many standalone tools in the marketplace that help monitor the many elements, but these tools create risks. Standalone tools can’t measure the entire stack holistically, and as a result, your team goes into reactive mode if any application availability issues surface. You’ll eventually know when an application isn’t available because end users everywhere will be calling the help desk (a situation we’d all prefer to avoid), but will you know what the cause is?
Can you prevent further service issues with a dispersed, decentralized monitoring strategy?
Before you gamble with your gold, consider these five tasks where our standalone monitoring tool doesn’t measure up.
No. 1: Monitoring the full application delivery stack from a single location
Using centralized monitoring solutions, such as Microsoft System Center Operations Manager (SCOM), you can monitor your full application stack from a single location and correlate events from different parts of the system.
For example, you can use System Center 2012 Management Pack for Microsoft Windows Server 2012 Internet Information Service 8 to monitor the IIS servers on which your application is running, and HYCU SCOM Management Pack for F5 BIG-IP to monitor F5’s BIG-IP appliances that load balance access to the IIS application. This approach gives you full monitoring visibility across the complete application delivery stack in one screen.
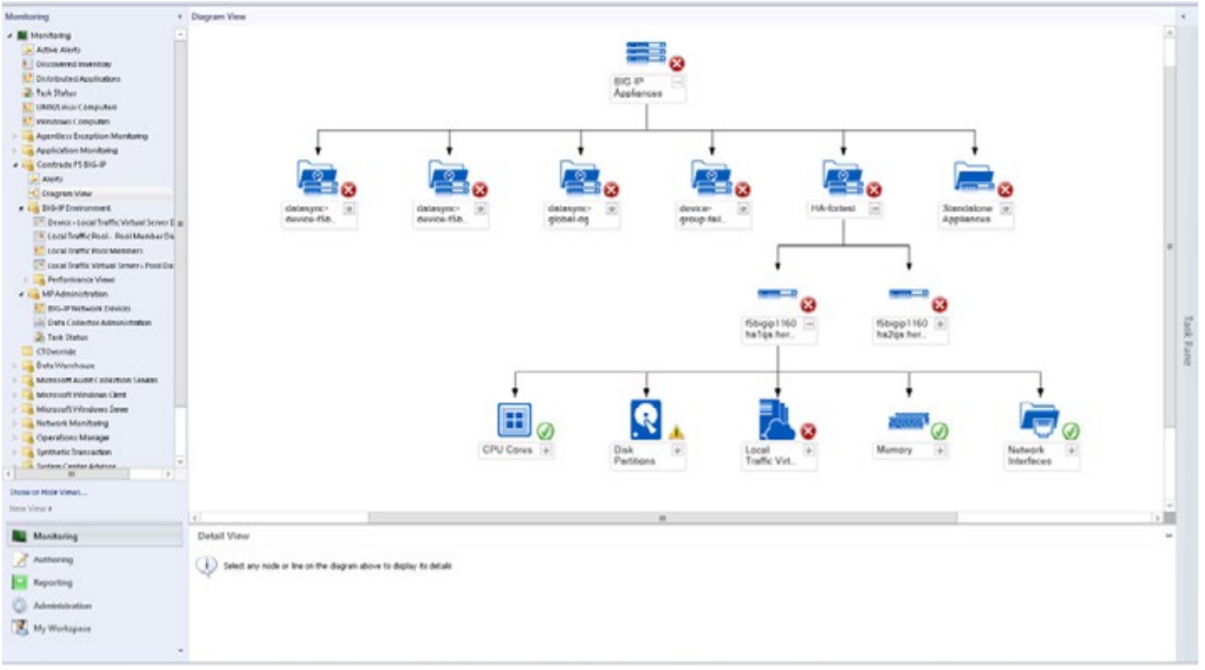
No. 2: Centralized, ad hoc, drill down reporting over extended periods of time
When you design your IT environment, you need to build in a monitoring technology that will report back to you the health status of all the hosted application services. When using standalone solutions, you can view statistics and performance for a single device or solution, but consolidating the information into a data center-wide report is a painful, manual process. Enter the centralized monitoring solution to the rescue.
For example, if you use HYCU SCOM Management Pack for F5 BIG-IP to monitor your F5 BIG-IP appliances, the management pack will collect and store historical information about every virtual server across all BIG IPs, and you’ll be able to generate ad hoc, drill down reports to analyze the most common issues of your BIG-IP configurations, servers and service availability over a time period.
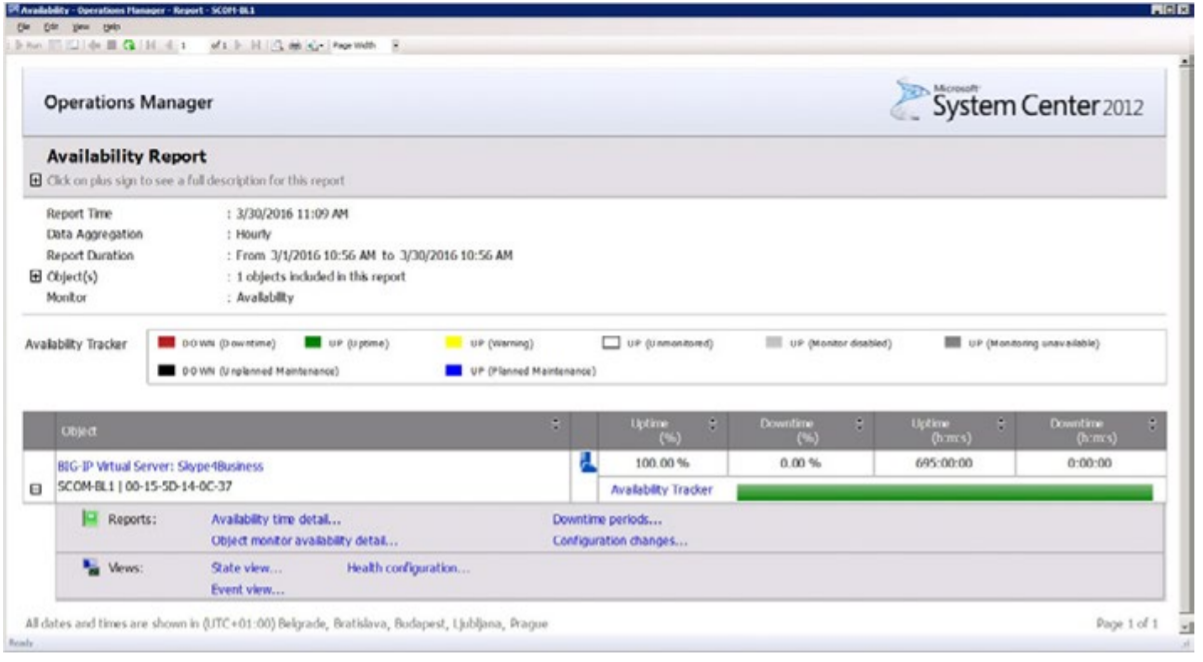
No. 3: Implement standardized procedures on top of single technology to monitor everything in the data center
Running a data center with standardized procedures is a very efficient way to cut costs. Trying to standardize when using several different standalone monitoring tools (perhaps based on different platforms) with different criteria to find relevant information is ineffective. It’s better to train your staff on a single monitoring technology that allows you to develop standardized procedures. A scalable, centralized monitoring platform will most likely enable you to monitor your complete data center, including your applications, infrastructure and network.
No. 4: Easily reconfigure and integrate to fine tune monitoring
Monitoring platforms are not islands unto themselves. They are part of your data center ecosystem, and it is critical for you to easily integrate the data you gathered when monitoring other systems in your enterprise. For example, a virtual server critical availability alert or CPU warning alert can be routed to Level 1 or 2 engineers, or event issue tracking systems.
If you are running a big data center, you know how much time can be wasted chasing false alerts.
Even if someone is just testing the virtual server, you could end up with thousands of false alerts, a maelstrom in itself, but also opening you up to the risk of overlooking some real alerts in the midst of the alarm storm.
Centralized monitoring solutions are customizable, allowing you to fine tune monitoring to your needs. For instance, using Microsoft SCOM and the F5 BIG-IP management pack you can disable, enable or customize specific monitors for the test virtual servers, therefore planning in advance to eliminate alerts from the test environment, and only receive alerts when there’s a real cause for concern.
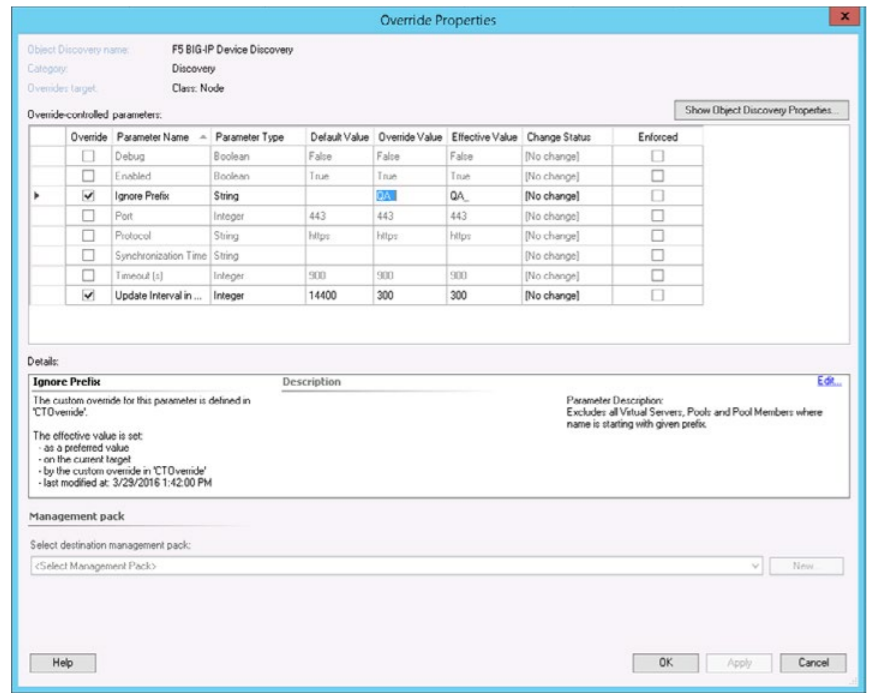
No. 5: Achieve easy setup to get quick time to value
Having a centralized monitoring platform is great.
From a single pane of glass, you can generate reports across your data center, use standardized procedures for all the components you monitor and fine-tune your environment. That’s what any good centralized monitoring platform will do.
The best centralized monitoring tools are easy to install, and therefore have a short “time to value” window.
You really want to be up and running in virtually no time, without spending months to educate your staff, handcraft all the configurations (every time something changes) and understand the technology and tools inside out.
Setting up everything by yourself requires you to be a monitoring domain expert – knowing what’s important and what is not – about every product you monitor. There’s an easier way: Microsoft IIS can let you know automatically what’s important, and HYCU engineers can pass on their knowledge about F5 BIG-IP.
Conclusion
If you have more than a single element to monitor, centralized monitoring solutions are your best bet. Monitoring the full stack, using standardized procedures, based on proven, easy to configure, technology with extended reporting across all monitored components shows the past, present and future all in one place.



Get the newest insights and updates
By submitting, I agree to the HYCU Subscription Agreement , Terms of Usage , and Privacy Policy .