
Jiraクラウドの役割 (バックアップとリストアが重要な理由)
どのような重要なシステム データでもそうですが、データの整合性、ビジネスの継続性、および災害復旧を確実にするためには、定期的なバックアップが不可欠です。
これは、膨大な量の重要なプロジェクト管理データを保持することが多いプラットフォームであるJiraにも同様に当てはまります。侵害された場合、プロジェクトの実行に大きな混乱が生じ、チームの生産性が低下し、全体的な事業運営に悪影響が及ぶ可能性があります。このような場合、データのバックアップの出番です。
これらのシナリオを見てみましょう:
- ビジネスの継続性。Jira はタスク、課題、およびプロジェクトの進捗を追跡するために広く使用されています。災害が発生した場合、組織は大きな混乱に見舞われ、プロジェクトの納品遅延、データ損失、潜在的な財務的影響につながる可能性があります。
- ヒューマン エラーからの保護
- 。どんなに几帳面なユーザーでも、チケットを誤って削除したり、重要なデータに影響を与える変更を加えたりすることがあります。このような削除は、特に多くの利害関係者がいる大規模なプロジェクトでは、重大な影響を及ぼす可能性があります。ソフトウェアの更新や新しいプラットフォームへの移行など、システムの変更を実施することには固有のリスクが伴います。そのようなイベントの前にバックアップを取ることで、セーフティネットが提供され、複雑な問題が発生した場合に安定した状態に戻すことができます。
- サイバーセキュリティの回復力。ランサムウェアのようなサイバー攻撃で、データが暗号化されたり削除されたりする可能性がある場合、最新のバックアップを持つことは非常に重要です。
アトラシアン クラウドのバックアップを開始する前に確認すべき3つのこと
アトラシアン クラウドの移行の準備には、スムーズな移行と貴重なデータの損失の可能性を軽減するための慎重な計画が必要です。
バックアップの頻度 (RPO)
RPO (Recovery Point Objective) は、ビジネスに大きな損害を与えることなく失われる可能性のあるデータの最大量を表します。
より簡単に言うと、RPO は質問に答えるものです:「問題になる前に、どれだけのデータを失う余裕があるか
Atlassian Cloud Backup、またはその他のバックアップ ソリューションを検討する場合、RPO を理解し確認することは、次の理由から非常に重要です:
- データ損失の許容。RPOを決定することで、基本的に、どれくらいの最近のデータを損失してもよいかというベンチマークを設定することになります。たとえば、RPO が 24 時間に設定されている場合、1 日分の作業までのデータ損失は許容できるということになります。
- バックアップの頻度。RPOは、バックアップを取る頻度に直接影響します。RPOが低い場合、たとえば1時間であれば、1時間分以上のデータを失う余裕はないことを意味します。その結果、この目標を達成するには、1 時間ごとにバックアップを実行する必要があります。
- リソースの割り当て。RPOを理解することで、リソースをより効率的に割り当てることができます。RPOが厳しい場合、その目標を確実に達成するために、より多くのストレージ、より高速なネットワーク、あるいは専用のバックアップ ソリューションが必要になるかもしれません。
- コストへの影響。バックアップの頻度が高くなると、ストレージと、これらのバックアップを管理および監視するために必要なリソースの両方において、コストが高くなる可能性があります。RPO を設定および検証することで、コストとデータ損失のリスクのトレードオフのバランスをとることができます。
目標復旧時間 (RTO:Recovery Time Objective)
RPO(目標復旧時間)が損失を許容できるデータ量に重点を置くのに対し、RTOはそのデータを復元し、中断後にシステムをオンラインに戻すのにかかる時間に重点を置きます。
要するに、RTOは質問に答えるものです:「重大な問題になる前に、どれくらいの時間、業務が停止できますか」
たとえば、業務停止時間に関して、RTO は、インシデント発生後にどれくらいの速さで業務を復旧させる必要があるかという目標を設定します。
データ保持
とは、データのバックアップが上書きまたは削除されるまでの期間を決定するポリシーと戦略のことです。
必要なときに過去のデータにアクセスできるようにするだけでなく、ストレージ コストの管理や規制要件の遵守にも役立ちます。
さらに、バックアップは時間の経過とともにかなりのストレージ容量を消費します。明確なデータ保持ポリシーを設定することで、ストレージの使用量を管理および最適化し、不必要に古いバックアップを保存しないようにすることができます。
💡関連→ The 7 Best Jira Cloud Backup Providers Now
Atlassian はエクスポートを提供しています:しかし、それだけでは十分ではありません
アトラシアンは Jira Cloud の「バックアップ」機能を提供していますが、そのプロセスは自動化されておらず、データ損失やシステム障害の際の完全な復旧を保証するものではありません。
たとえば、アトラシアンのネイティブなクラウドバックアップ機能は、データの XML バージョンを 48 時間ごとに提供するだけです。
つまり、
- データを完全にエクスポートできるのは 48 時間に一度だけです。
- 復元できるのはインスタンスのみで、粒度の細かいデータは復元できません。したがって、開発者が Jira、Confluence、または JSM で特定のプロジェクト、課題、または添付ファイルを削除した場合、回復ポイントはありません。
- データを手動でコピー/エクスポートするか、スクリプトウィザードでこれを簡単にする方法を見つける必要があります。手動でデータをエクスポートすると時間を消費し、スクリプトを管理すると複雑さが増し、常に管理が必要になります。
これは Jira にとって何を意味するのでしょうか
ネイティブの Atlassian Cloud 「バックアップ」 はデータの大量エクスポートに過ぎないため、データ損失や偶発的な削除が発生した場合に組織のデータを回復できる保証はありません。
ネイティブなアトラシアン バックアップの具体的な制限事項:
- 削除された粒度の細かいデータを復元できない
誤って Jira から壮大なプロジェクトを削除してしまった場合、エクスポートからタイムリーに復元することはできません。
- 何時間も何日もかけてバックアップを作成しても、「粒度の細かいリストア」機能はありません。
- データ保持ポリシーに準拠していないデータ保持ポリシーを持つ業界は多く、すべての組織が準拠しなければなりません。たとえば、米国のヘルスケア企業は医療保険の相互運用性と説明責任に関する法律 (HIPAA) を遵守する必要があり、少なくとも 7 年間はデータを保存する必要があります。一方、Atlassian Cloud は 30 日後にデータを削除しますが、これはエクスポートされたデータが必要な期間使用できなかったり、簡単にアクセスできなかったりする可能性があるため、保持ポリシーに沿わない可能性があります。
ランサムウェア攻撃の影響を受けやすい。サイバー犯罪者が Atlassian Cloud 環境内の重要なデータを暗号化した場合、不変のコピーがないため、エクスポートされたバックアップから盗まれたデータを復元するのは難しいかもしれません。
たとえば、ネイティブなアトラシアンのバックアップソリューションはアトラシアンクラウドに依存しているため、プラットフォームの一部を危険にさらすサプライチェーンアタックがあった場合、データが暗号化される危険性があります。
👀 余談 → サプライチェーンアタックとは、ソリューションのサプライチェーン内の脆弱性を狙ったサイバー攻撃の一種です。
プロからのヒント → HYCUでは、バックアップの頻度と保存期間を管理できます。HYCUを無料で試す👈
Different Native Atlassian Cloud Backup and Restore Processes
自動バックアップ
残念ながら、アトラシアンは Jira Cloud の自動バックアップ機能を提供していません。バックアップが必要なたびに手動でバックアップを作成する必要がありますが、これは時間がかかり、一貫性のないバックアップにつながる可能性があります。
さらに、ビルトインのバックアップ機能では、バックアップをトリガーするために手動で操作する必要があり、特定のプロジェクトや課題の種類を選択することなく、すべてのデータがバックアップされます。
この絶え間ない問題を解決するには、アトラシアンマーケットプレイスで利用可能なサードパーティのアプリケーションを探すことです。HYCU、BackUp for Jiraなど、いくつかのバックアップソリューションは、手動で操作することなく、自動化されたスケジュールバックアップを提供できます。
Jiraクラウド用のバックアップアプリの設定と使用
- HYCUのようなバックアップソリューションを選択したら、インストールして設定する必要があります。
- Jiraインスタンスから、[アプリ] > [新しいアプリの検索]に移動します。
- HYCUを検索し、[インストール]をクリックします。
- インストール後、[アプリ]>[アプリの管理]に移動し、リストでHYCUを見つけます。
- アプリを開き、プロンプトに従ってバックアップ設定を構成します。バックアップ スケジュールを設定し、バックアップするデータを選択し、バックアップ先を選択します。
手動バックアップ
Jira で手動バックアップを作成する方法は 2 つあります。
-
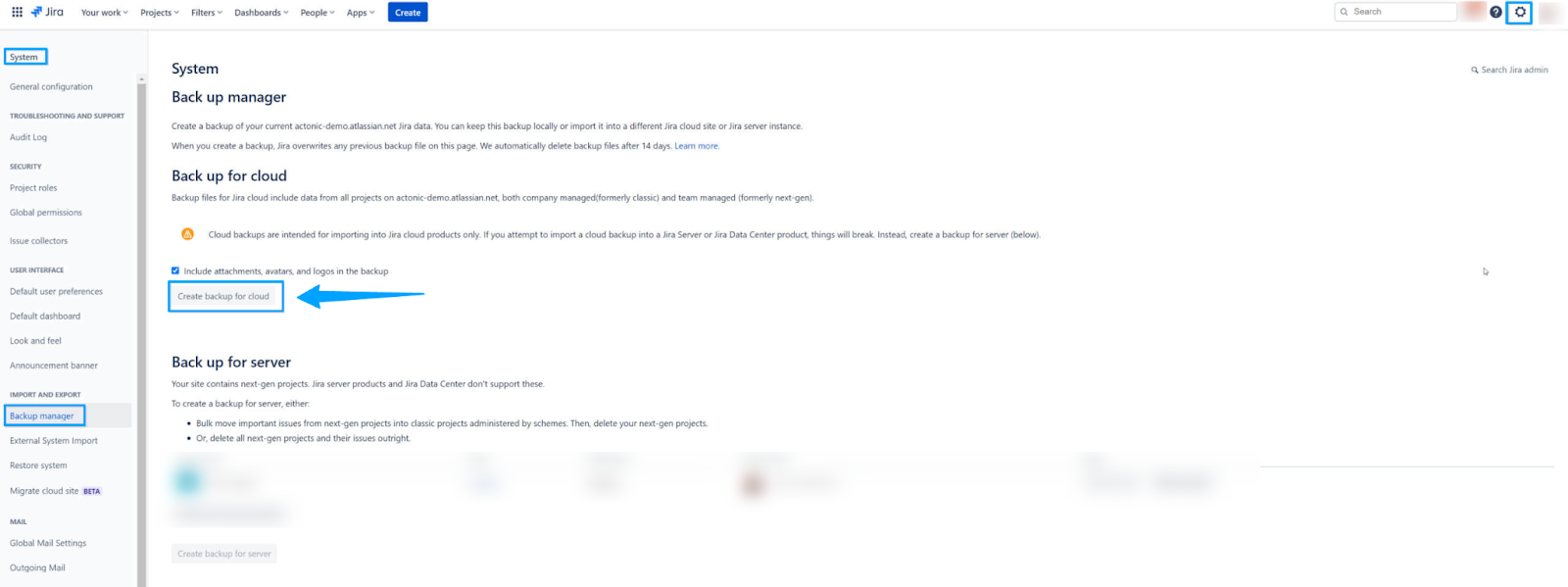
バックアップファイルを作成するために Jira Cloud インターフェイスを使用する方法。
- 管理者として Jira Cloud アカウントにログインします。
- 管理セクションに移動します。
- 設定 → システム
- 「IMPORT」および「EXPORT」セクションの下で、「バックアップマネージャー」を選択します。
- 「クラウド用バックアップ」の下で、「クラウド用バックアップを作成」をクリックします。
- バックアップが作成されたら、「バックアップをダウンロード」をクリックし、バックアップファイルをローカルストレージに保存します。
スクリプトと cron ジョブの使用
ステップ 1.Atlassian API キーを取得します。
- アトラシアンアカウントにログインします。
- 「アカウント設定」に移動します。
- 「セキュリティ」をクリックし、「API トークン」をクリックします。
- 「API トークンを作成」をクリックし、名前を付けます。
- トークンをクリップボードにコピーします。スクリプトを認証するために必要です。
ステップ 2.バックアップスクリプトリポジトリをクローンします。
- アトラシアン API を使用してバックアップを作成するカスタムスクリプトを作成します。あるいは、サードパーティが提供するスクリプトを使用することもできます。
- Git を使用して、スクリプトを含むリポジトリをローカルマシンまたはサーバーにクローンします。
注意点 → このスクリプトは通常、ステップ 1 で取得したアトラシアン API キーを使用して Jira インスタンスを認証し、アクセスします。スクリプトには、ストレージスペースを節約するために古いバックアップを削除するなど、バックアップファイルを管理するロジックも含まれます
ステップ 3.cron ジョブを設定する
バックアップスクリプトが配置されている場所に cron ジョブを作成します。cronジョブは、バックアップスクリプトを実行する頻度を定義します(毎日、毎週、毎月など)
この方法は次のとおりです:
- ターミナルで「crontab -e」を実行し、crontabファイルを編集するために開きます。
- 次の形式で新しい行を追加します:
* * * * /path/to/script > /path/to/logfile- cron ジョブは指定された間隔でバックアップスクリプトを実行し、Jira Cloud インスタンスのバックアップを作成します。
cron式に関する重要な注意
上に示したように、5つのアスタリスクは(順番に)分、時、月、日、曜日を表します。
これらを調整してバックアップの頻度を設定します。アスタリスクの後のパスはスクリプトを指しているはずです。
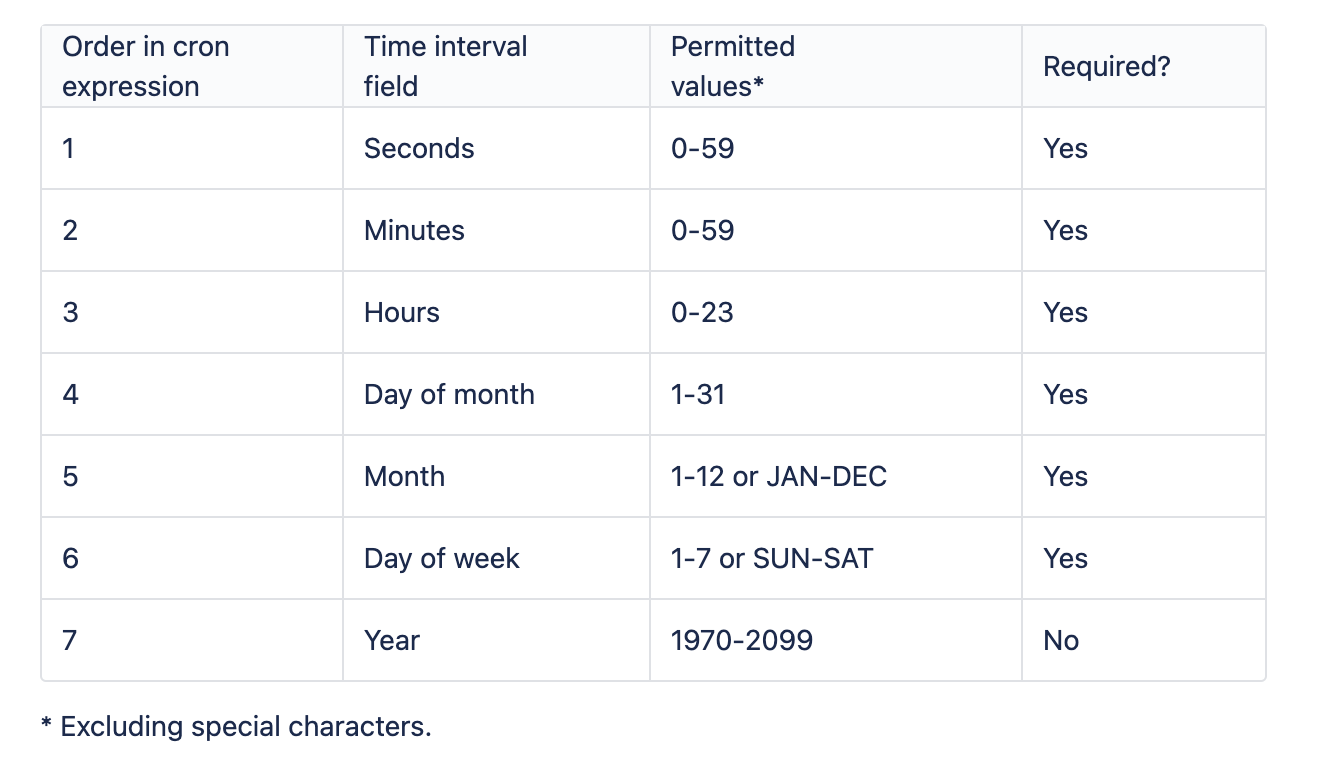
簡単な例として、この完全なcron式を示します:"0 0 12?
WED" - これはトリガーが "毎週水曜日12:00:00 "に設定されていることを意味します。
おすすめ記事 💡 →cronトリガーの設定に関する詳細はこちら ︓
バックアップスクリプト
バックアップスクリプト(その名の通り)には、データのバックアップと復元を自動化するためのスクリプトやプログラムを書くことが含まれます。
さまざまなスクリプト言語でこれを行うことができますが、ここではPythonとBashに焦点を当てます。
Python
Pythonは高レベルのインタプリタ型プログラミング言語で、読みやすさと多用途性で知られています。
APIと相互作用し、ファイル操作を処理し、バックアップおよび復元プロセスで必要な他のさまざまなタスクを実行できる、豊富なライブラリとモジュールのセットがあります。Pythonはプラットフォームに依存しないので、異なるオペレーティングシステム上で実行する必要があるスクリプトタスクに適しています。
以下に例を示します:
Pythonバックアップスクリプト
import requests API_TOKEN = 'your_api_token' API_URL = 'https://your-instance.atlassian.net/wiki/rest/backup' headers = { 'Accept': 'application/json'、 'Authorization': f'ベアラ{API_TOKEN}'、 } response = requests.post(API_URL, headers=headers) if response.status_code == 202: print('バックアップが正常に開始されました') else: print(f'バックアップの開始に失敗しました: {response.content}')Pythonリストアスクリプト
import requests API_TOKEN = 'your_api_token' API_URL = 'https://your-instance.atlassian.net/wiki/rest/restore' BACKUP_FILE_PATH = '/path/to/your/backup.tar' ヘッダー = { 'Accept': 'application/json'、 'Authorization': f'ベアラ{API_TOKEN}'、 } with open(BACKUP_FILE_PATH, 'rb') as backup_file: response = requests.post(API_URL, headers=headers, files={'file': backup_file}) if response.status_code == 202: print('Restore started successfully') else: print(f'リストアの開始に失敗しました: {response.content}')Bash
Bash (Bourne Again SHell)は、Unix/Linux オペレーティングシステム用のコマンドライン インタープリター、またはシェルです。
Bashで書かれたスクリプトは通常、ファイルやシステムの操作に使用されます。また、Unix/Linuxシステムで実行されるバックアップスクリプトにも適しています。また、Bashスクリプトはシステムレベルのタスクと直接やり取りできるため、バックアップやリストア操作に非常に強力です。
以下に例を示します:
Bashバックアップスクリプト
API_TOKEN="your_api_token" API_URL="https://your-instance.atlassian.net/wiki/rest/backup" response=$(curl -X POST -H "Accept: application/json" -H "Authorization:ベアラ $API_TOKEN" $API_URL) if [ $? -eq 0 ]; then echo "バックアップが正常に開始されました" else echo "バックアップの開始に失敗しました: $response" fiBashリストアスクリプト
API_TOKEN="your_api_token" API_URL="https://your-instance.atlassian.net/wiki/rest/restore" BACKUP_FILE_PATH="/path/to/your/backup.tar" response=$(curl -X POST -H "Accept: application/json" -H "Authorization:ベアラ $API_TOKEN" -F "file=@$BACKUP_FILE_PATH" $API_URL) if [ $? -eq 0 ]; then echo "リストア成功" else echo "リストアの開始に失敗しました: $response" fi注意 → 実際のAPIエンドポイントやメソッドは、特定のアトラシアン製品やバックアップ/リストア操作の種類によって異なる場合があります。
最も正確で最新の情報については、公式のアトラシアン API ドキュメントを参照することをお勧めします。
Jira Cloud バックアップと復元のプロセス
Jiraクラウドのデータと設定を復元するためのステップバイステップのガイドです:
ステップ 1.バックアップファイルを準備します。
リストア プロセスのために有効なバックアップ ファイルが準備されていることを確認します。
前述したように、このバックアップは Jira Cloud のバックアップ マネージャー、サードパーティのツールまたはバックアップ スクリプト、および cron ジョブを使用して作成した zip ファイルである必要があります。
- データを復元するために必要なすべての権限とアクセス権を持っていることを確認します
- 既存のデータをバックアップします(任意ですが、推奨します)
ステップ 2.
- 管理者として Jira Cloud インスタンスにログインします。
- 設定 (歯車のアイコン) > システム > バックアップ マネージャーをクリックしてバックアップ マネージャーに移動します。
- バックアップ マネージャーで「リストア」セクションの下にある「ファイルを選択」をクリックします。
- バックアップ ファイルを探して選択します。
- 「リストア」ボタンをクリックしてリストア プロセスを開始します。これによって Jira Cloud インスタンスの既存のデータがすべて上書きされることを忘れないでください。
注意事項 → 復元プロセスには、バックアップのサイズによって時間がかかる場合があります。プロセスが完了するまで中断しないでください。
ステップ3.リストアされたデータの確認とテスト
- リストア プロセスの完了後、データと設定が正しくリストアされたことを確認します。これには、課題、ワークフロー、権限、ユーザー データ、およびその他の設定が含まれます。
すべてのデータが無傷であることを確認するために、異なるプロジェクトのデータのサンプルを確認する必要があります。
- Jira Cloud インスタンスが正しく動作していることを確認します。
- これには、課題の作成と編集、ワークフローの開始と完了、課題の検索などが含まれます。
- インストールされているアプリとアドオンを確認し、復元後に正しく機能することを確認します。
Jira Cloud バックアップを他のアトラシアン製品と統合する
アトラシアンの製品群は、プロジェクト管理 (Jira Software)、サービス管理 (JSM)、コラボレーション (Confluence) のためによく一緒に使用されます。
そのため、これらのツール間で一貫した信頼できるバックアッププロセスを確保することは非常に重要です。ここでは、Jira Cloud バックアップと統合できるアトラシアン製品を紹介します。
- Jira と Confluence の統合。Jira と Confluence は密接に連携することが多いため、両方の製品で一貫したバックアップ戦略を持つことは有益です。実際、多くのバックアップアプリやスクリプトは Jira と Confluence の両方を同時にサポートするように設計されており、両方のアプリケーションのバックアップをスケジュールし管理することができます。
- Jira Service Management (JSM) 統合。JSM はしばしば Jira Software と共に使用されます。そのため、これら 2 つのシステム間のデータは緊密にリンクされているため、バックアップはデータが同期されたままであることを保証するために同時に行うのが理想的です。また、いくつかのバックアップソリューションは Jira Service Management を特にサポートしており、全体的なバックアップ計画に含めることができます。
- Bitbucket との統合。Bitbucket はアトラシアンのバージョン管理システムで、Jira とシームレスに統合するいくつかの機能を提供しています。例えば、アトラシアンは Bitbucket データセンター向けにスクリプトベースの DIY バックアップ戦略を提供しています。また Bitbucket Cloud では、ワークスペースのデータをエクスポート・インポートできます。
一方、バックアッププロセスがアトラシアンの製品間で一貫していることを確認するために:
- バックアップスケジュールを同期する。バックアップスケジュールを同期して、すべてのアトラシアン製品のデータを同時にバックアップするようにしましょう。これにより、これらのツールのデータが一貫し、同じ時点を反映するようになります。
- 統合バックアップソリューションを使用する。すべてのアトラシアン製品をサポートする HYCU のようなサードパーティのバックアップソリューションの使用を検討してください。これにより、単一のインターフェイスからバックアップを管理・監視できるようになり、バックアッププロセスが簡素化されます。
プロのヒント → Jira のあらゆるデータ (特定の添付ファイル、課題、サブタスクまで) をワンクリックで復元できます!
Jiraクラウドのバックアップアプリが提供する使用例と追加機能
バックアップアプリが提供する一般的な自動化機能のほかに、多くのアプリにはバックアップとリストアプロセスを強化する機能があり、データ保護と効率的なディザスタリカバリを保証します。
これらのアプリが提供する追加機能とその使用例には次のようなものがあります:
- 選択的バックアップ。一部のアプリでは、インスタンス全体ではなく、特定のプロジェクトやissueタイプをバックアップできる選択バックアップが可能です。
- バックアップストレージオプション。HYCUは、ローカルストレージ、クラウドストレージ(Amazon S3、Google Cloud Storage)、または専用のバックアップサービスなど、さまざまなストレージオプションを提供する唯一のソリューションです。
- データの暗号化とセキュリティ。多くのバックアップアプリは、保存されたバックアップファイルの暗号化オプションを提供することで、データのセキュリティを優先しています。
- バックアップの検証
- .アプリによっては、バックアップファイルの完全性を保証するための検証メカニズムが組み込まれています。バックアップに対して定期的なチェックを行い、データがエラーなく復元可能であることを確認します。
関連 → The 14 Best SaaS Backup Providers Now
Managing Backup and Restore Tasks for Multiple Jira Cloud Sites
複数のJira Cloudサイトを管理する場合、効率的なバックアップとリストア管理が不可欠です、効率的なバックアップとリストア管理が不可欠です。
- 一元管理。
- 一括操作。複数のサイトで一括バックアップまたはリストアを実行するバックアップアプリを選択します。これにより、多数のインスタンスを扱う際の時間と労力を節約できます。
- サイト間での一貫性。
- スケジュールされた同期とミラーリング。場合によっては、複数のインスタンス間で同期されたバックアップを維持したいと思うかもしれません。
- スケジュール同期とミラーリング
サードパーティのバックアップ アプリは、追加の機能と利便性を提供できますが、データが安全にバックアップされ、必要なときに復元できるように、適切な設定と管理も必要であることを忘れないでください。
構築と購入:Jira バックアップ
適切な Jira バックアップ ソリューションを見つける場合、2 つのオプションのいずれかを選択することになります。
- 制限のあるアトラシアンのビルトインエクスポートを使用するか、
- 高度なサードパーティソリューション (HYCU など) を使用して、Jira Cloud でのデータ保護とデータ損失のリスクを最小限に抑えるか
この記事で説明したことを踏まえると、アトラシアンのオプションを選択することは、バックアップの完全性とセキュリティにより多くのリスクをもたらします。
たとえば、特定のプロジェクト、構成、課題、添付ファイルをリストアする必要があるかもしれません。しかし、Jira Cloud の組み込みのバックアップ ソリューションは選択的なリストアをサポートしていません。
そのため、HYCU は、データ損失を最小限に抑え、予期せぬインシデントに直面しても迅速に復旧し、バックアップを自動化し、AWS、Google Cloud、または Wasabi へのオフサイトストレージを確保したい組織にとって、魅力的な選択肢となります。
HYCUでJira Cloudをバックアップ
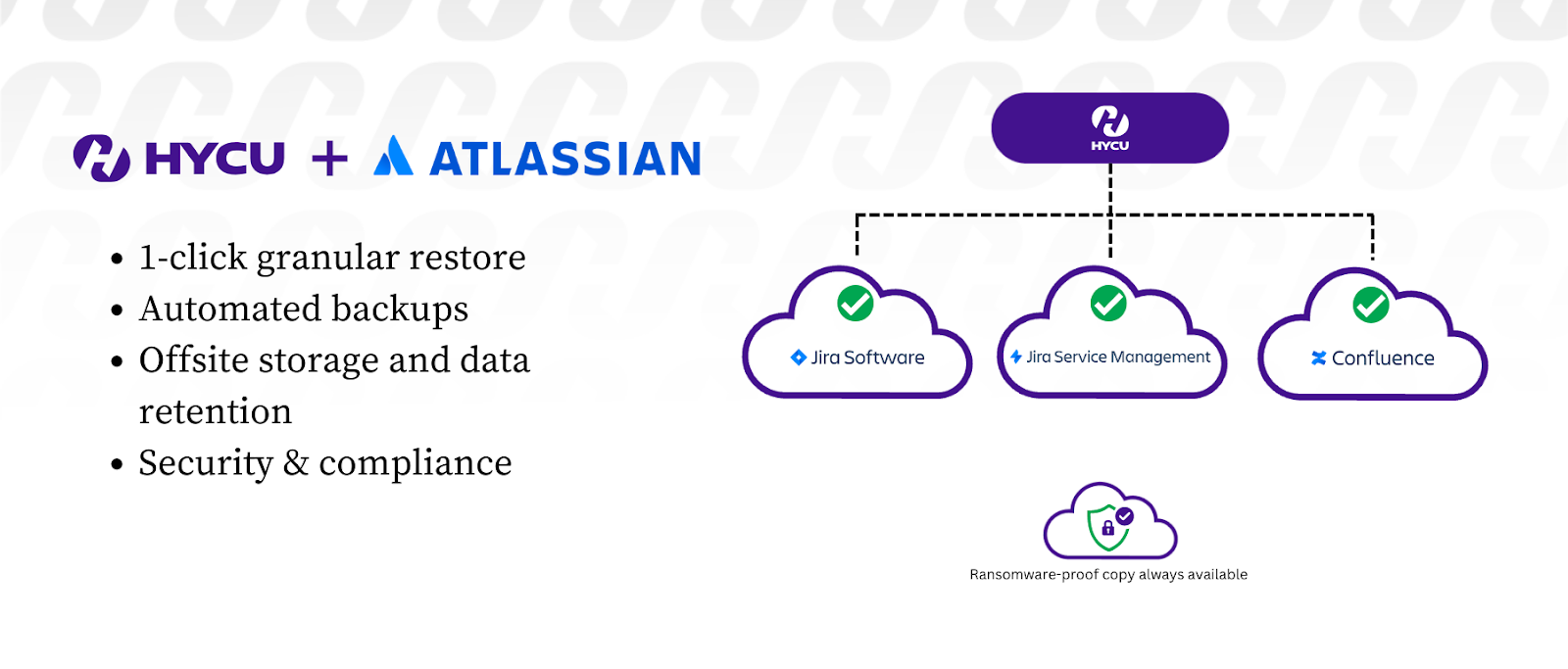
- 1 クリックできめ細かくリストア。HYCUのきめ細かなリストア機能では、回復ポイント目標(RPO)に基づいて、特定のプロジェクト、課題、構成、および添付ファイルをワンクリックでリストアできます。このレベルのきめ細かさにより、バックアップ全体のリストアに費やしていた時間を節約できます。
- 数回のクリックですべてのバックアップ操作を自動化
- HYCUはJiraデータのバックアッププロセスを簡素化する自動バックアップ機能を提供します。例えば、数回クリックするだけで、バックアップの頻度やタイミングを設定することができ、常に手作業を必要としません。
- データをオフサイトに保存することでコンプライアンス要件に対応 Jira データをオフサイト (別の場所) に保存することで、サイトを標的とした攻撃や偶発的な削除に対する保護を強化できます。HYCUは、Jiraデータのバックアップコピーをオフサイトに保管し、PCI、HIPAA、SOX(Sarbanes Oxley)、GDPRなどのコンプライアンス要件を満たすことでこれを支援します。
- データの「ランサムウェア対策」コピーの保管を支援ランサムウェア攻撃によってプライマリJiraクラウド環境が暗号化または侵害されるリスクを軽減するために、データの不変コピーをAWS、Googleクラウド、あるいはWasabiのようなS3互換のストレージターゲットに保管することができます。
関連 → データの不変性はランサムウェア保護への最も強力なアプローチですか
FAQ:Jiraバックアップと復元
Jira Cloudデータのバックアップを手動で作成できますか?
はい、アトラシアンの組み込みバックアップ機能を使用して Jira Cloud データのバックアップを手動で作成できます。ただし、自動バックアップには対応していません。
関連 → 中小企業向けバックアップ ソリューション トップ 8 (クラウドおよびオンプレミス)
Jiraデータのバックアップはどのくらいの頻度で行うべきですか?
バックアップの頻度は、データの変更頻度によって異なります。
Jira Cloud の自動バックアップを有効にするにはどうすればよいですか?
アトラシアンマーケットプレイスのサードパーティ製アプリ/アドオンを使用して、Jira Cloud で自動バックアップを実行できます。また、アトラシアン API を活用してスクリプトを使用することもできます。
バックアップファイルから Jira Cloud インスタンスを復元するにはどうすればよいですか?
アトラシアンの組み込みのリストア機能を使用すると、バックアップファイルから Jira Cloud インスタンスをリストアできます。
Jira Cloud のバックアップ戦略のベストプラクティスにはどのようなものがありますか?
ベストプラクティスには、定期的なバックアップ、バックアップファイルの完全性の検証、選択的バックアップの使用、バックアッププロセスの自動化、組織が管理するストレージターゲットへのオフサイトでの安全なバックアップの保存などがあります。
スクリプトやAPIを使用してバックアッププロセスを自動化できますか?
はい、Python や Bash などのスクリプト言語とアトラシアンの API を組み合わせて、バックアッププロセスを自動化できます。
Jira Cloud のバックアップファイルはどこに保存すべきですか?
バックアップファイルはアトラシアン以外の場所に安全に保存する必要があります。イミュータブルコピーが可能なパブリッククラウドまたは S3 互換のストレージターゲットを推奨します。
3-2-1バックアップストレージ戦略に従うことをお勧めします。
バックアップファイルはどのくらいの期間保持する必要がありますか?
バックアップファイルの保持は、組織のデータ保持ポリシーとコンプライアンス要件に基づいてください。
Jira Cloud バックアップを他のアトラシアン製品と統合できますか?
はい、多くのバックアップアプリは Confluence や Jira Service Management のような他のアトラシアン製品との統合をサポートしています。
Jira Data Center と Jira Server インスタンスにはどのようなバックアップオプションがありますか?
以下に Jira Data Center と Jira Server インスタンスのバックアップオプションを示します。
- ビルトイン XML バックアップ (Jira Server および Jira Data Center)
- Jiraデータセンター共有ホームディレクトリ (データセンターのみ)
- データベースバックアップ
- ファイルシステムバックアップ
- スナップショットおよび仮想マシンバックアップ
Jira Cloud バックアップのためにアトラシアンマーケットプレイスで検討すべきアドオンまたはアプリはどれですか?
-
HYCU は Jira Cloud バックアップのために非常に推奨されるオプションです。
- データ損失とダウンタイムを回避。
- プロジェクト全体から課題、サブタスク、添付ファイルまで、あらゆるものを復元
- 手動バックアップを排除
- 。
- データの保持とコンプライアンス
- 。組織が管理するストレージ ターゲットのオフサイトに、必要な期間だけデータを保存する機能により、データの保持基準とコンプライアンスを満たすことができます。
特定の時間に自動的にバックアップを実行するようにスケジュールできますか?
はい、サードパーティのアプリやスクリプトを使用して、自動バックアップをスケジュールできます。最低でも毎日バックアップすることをお勧めします。
どのように Jira Cloud バックアップ ファイルの整合性を確認できますか?
一部のバックアップ アプリはバックアップ検証機能を提供しています。あるいは、本番環境以外でテスト リストアを実行することもできます。


最新の知見や最新情報を入手しましょう
By submitting, I agree to the HYCU Subscription Agreement , Terms of Usage , and Privacy Policy .