
Google Cloud. HYCU protège plus de services Google Cloud que toute autre solution ou service de sauvegarde. En reconnaissance de cette innovation de longue date pour les utilisateurs de Google Cloud, Google a nommé HYCU Google Cloud Partner of the Year for Backup and DR lors de Google Cloud Next 24 à Las Vegas pour son engagement continu à élever la barre de la résilience et de la récupération des joyaux de la couronne de ses clients, leurs données.
Google Cloud est souvent appelé affectueusement "The Data Cloud", avec son portefeuille de données extrêmement robuste. Google BigQuery est la pièce maîtresse de la stratégie de Google en matière de données et constitue la plateforme de données unifiée qui permet aux utilisateurs de stocker, d'analyser et de visualiser des données multimodales de plusieurs pétaoctets.
BiqQuery est un service entièrement géré qui prend en charge les données structurées et non structurées, y compris les formats de table ouverts ; prend en charge plusieurs moteurs de traitement ; traite les données sur plusieurs nuages ; ingère les données par lots et par flux en temps réel (IOT, flux de médias sociaux, événements, etc.).)
À l'ère de l'IA, il est important de noter que l'IA vient là où se trouvent les données et non l'inverse. Avec BigQuery ML, les modèles d'IA sont démocratisés et rendus accessibles à toute personne ayant des compétences SQL de base. BigQuery devient ainsi l'une des charges de travail les plus stratégiques pour toutes les entreprises. De nombreux leaders du secteur, tels que Walmart, Spotify, Wayfair, Home Depot, Ford et Palo Alto Networks, s'appuient sur BigQuery comme plateforme de données de choix.
Pour garantir que vos données Google BigQuery sont correctement protégées dans plusieurs domaines de défaillance, vous aurez besoin d'une sauvegarde et d'une restauration de classe entreprise qui soient complètes dans ce qu'elles protègent, cohérentes dans les ensembles de données dépendants et granulaires lors de la restauration. HYCU R-Cloud est la première et la seule solution de sauvegarde d'entreprise à ajouter la prise en charge de la sauvegarde et de la restauration pour Google BigQuery. Nous avons des clients qui protègent les données BigQuery à plusieurs TBs/minute.
Portant l'innovation pour BigQuery un pas en avant, HYCU supporte maintenant les Atomic Backup Sets pour BigQuery. Les jeux de sauvegarde atomiques sont conçus pour garantir la cohérence des vues et des requêtes de données réparties sur plusieurs ensembles de données dans BigQuery. Qu'il s'agisse d'ensembles de données dépendants de différentes sources ou de vues croisées entre différents ensembles de données, les organisations sont désormais protégées contre la perte de données bien plus longtemps que la semaine fenêtre de voyage dans le temps dont disposent les utilisateurs de BigQuery grâce à une copie cohérente.
Pourquoi la protection des données est importante pour BigQuery
La première raison pour laquelle vous devez protéger vos données BigQuery est la prévention de la perte de données. La perte de données dans Google BigQuery peut survenir pour un certain nombre de raisons, il est donc crucial d'être conscient des risques. Voici quelques scénarios courants :
- Défaillances au niveau de la zone et au niveau inférieur : des problèmes matériels ou de réseau dans une zone spécifique peuvent rendre vos données indisponibles, voire les perdre, si elles ne sont pas répliquées dans d'autres zones.
- Défaillances régionales : Des événements majeurs tels que des catastrophes naturelles peuvent affecter une région entière. Si vos sauvegardes ne sont stockées que dans cette région, vous risquez de perdre l'accès à vos données au moment où vous en avez le plus besoin.
- Bugs dans le code SQL : de petites erreurs dans les requêtes SQL peuvent accidentellement supprimer ou corrompre des données si des mesures de protection ne sont pas mises en place.
- Erreur humaine : Les suppressions accidentelles ou les mauvaises configurations peuvent entraîner une perte de données involontaire.
- Menaces internes : Des personnes autorisées peuvent intentionnellement supprimer ou faire fuir des données, ce qui pose de sérieux risques pour la sécurité de vos données.
Être conscient de ces risques vous aide à prendre des mesures pour protéger vos données dans BigQuery.
Le coût élevé de la recréation de votre ensemble de données BigQuery
Traditionnellement, les entrepôts de données sont une copie de données transformées provenant de sources multiples, et beaucoup se demandent pourquoi ils ont besoin d'être sauvegardés. Cependant, il est important de prendre en compte le temps et les coûts nécessaires pour recréer l'entrepôt en cas de perte durable de données. Les coûts comprennent :
- ETL(Extract, Transform, Load)
- Streaming
- API
- Pipeline services, egress, etc.
En outre, avec des systèmes de mise à l'échelle massive comme BigQuery, de nombreux clients s'appuient sur le streaming d'événements en temps réel pour alimenter l'entrepôt de données et, bien souvent, le recréer ne serait même pas possible car leur seule copie de données est stockée sous forme d'ensemble de données BigQuery.
Bien que les fonctionnalités de voyage dans le temps et d'instantané soient disponibles via le service, la protection au-delà de sept jours nécessite une sauvegarde. Les réglementations modernes comme DORA exigent un domaine de défaillance plus large pour les applications critiques. La plupart des secteurs réglementés, comme la santé et la finance, sont également soumis à des exigences de conformité, de conservation à long terme et de durabilité.
Pourquoi des ensembles de sauvegarde atomiques ?
Alors que BigQuery peut facilement traiter des ensembles de données massifs, il est courant que les utilisateurs de BigQuery segmentent leurs données en plusieurs ensembles de données. Cette segmentation leur offre un meilleur contrôle sur :
- Organisation et gestion des données
- Contrôle d'accès granulaire
- Performance et optimisation des requêtes
- Gestion des coûts de requête
- Gestion du cycle de vie des données/expiration des enregistrements
Même avec des ensembles de données segmentés, BigQuery offre plusieurs façons d'analyser et d'exploiter les données à travers ces ensembles de données grâce à des requêtes fédérées, des jointures inter-ensembles de données, des vues, etc. Les vues sont des tables virtuelles qui permettent d'encapsuler des requêtes complexes et de les présenter comme des tables simples. Les vues sont des tables virtuelles qui permettent d'encapsuler des requêtes complexes et de les présenter sous la forme de simples tables. Elles sont particulièrement utiles pour créer des requêtes réutilisables qui peuvent être partagées par différentes équipes et deviennent souvent la principale méthode de consommation des données par les utilisateurs de BigQuery.
Lors de la sauvegarde, il est donc important que ces ensembles de données sous-jacents soient protégés par une version datant du même moment afin de rendre ces vues fiables. Un autre point important à noter est qu'au fur et à mesure que ces ensembles de données s'agrandissent, les sauvegardes traditionnelles créent des fenêtres d'incohérence plus grandes, ce qui rend ces ensembles de sauvegardes atomiques plus critiques.
Il est également important de noter que l'exportation de données à partir de BigQuery n'inclut pas les données de voyage dans le temps et que vous ne pouvez pas remonter jusqu'à un point cohérent. Par conséquent, il est essentiel de pouvoir créer une cohérence coordonnée au moment de la sauvegarde.
Les ensembles de sauvegarde atomiques sont une nouvelle fonctionnalité puissante qui permet aux utilisateurs de regrouper des ensembles de données et de s'assurer qu'ils sont sauvegardés au même moment dans l'ensemble de l'ensemble. Cette fonctionnalité est particulièrement utile pour maintenir l'intégrité des données dans des ensembles de données connexes.
Avantages de l'utilisation des ensembles de sauvegarde atomiques
- Intégrité des données : garantit que les ensembles de données connexes sont cohérents les uns par rapport aux autres, en évitant les divergences qui peuvent résulter de l'exportation d'ensembles de données à des moments différents. Les vues qui font référence à des tables dans d'autres ensembles de données sont courantes et l'exportation de ces ensembles de données dépendants ensemble permet d'obtenir une meilleure cohérence.
- Gestion simplifiée : Le regroupement des ensembles de données facilite la gestion et l'organisation de vos exportations de données.
- Fiabilité accrue : En protégeant les ensembles de données au même moment, vous réduisez le risque de discordance des données et améliorez la fiabilité de votre analyse de données.
Comment est-il facile d'accomplir des ensembles de sauvegarde atomiques ?
Au sein de HYCU, nous nous efforçons toujours de rendre les choses faciles pour les clients. La création de jeux de sauvegarde atomiques est aussi simple que la création d'un label Atomic-Backup-set avec les ensembles de données associés étiquetés. Cette étiquette vous permet de définir quels ensembles de données doivent être regroupés. Lorsqu'une sauvegarde est lancée, tous les ensembles de données ayant la même valeur de label Atomic-Backup-set seront protégés en utilisant le même point dans le temps, garantissant ainsi un regroupement cohérent de vos données. Ce regroupement n'est aujourd'hui disponible que pour les ensembles de données BigQuery hébergés dans la même région.
Pour commencer avec les ensembles de sauvegarde atomiques
Pour commencer à utiliser les ensembles de sauvegarde atomiques dans vos sauvegardes BigQuery, suivez ces étapes simples :
- Étiqueter vos ensembles de données : Ajoutez l'étiquette Atomic-Backup-set aux ensembles de données que vous souhaitez protéger ensemble. HYCU affichera un nouveau groupe dans l'interface utilisateur R-Cloud en utilisant le format __
-
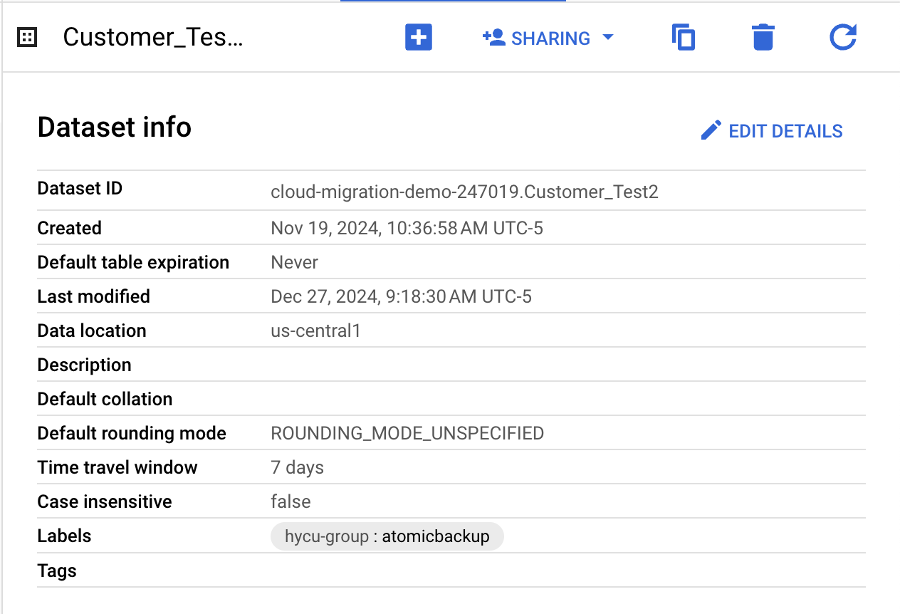
- Association de la politique : Associez votre politique de sauvegarde au nouveau groupe dans HYCU R-Cloud. Lorsque la politique lance la sauvegarde pour BigQuery, HYCU regroupera et sauvegardera automatiquement les ensembles de données BigQuery avec la même étiquette Atomic-Backup-set au même moment.
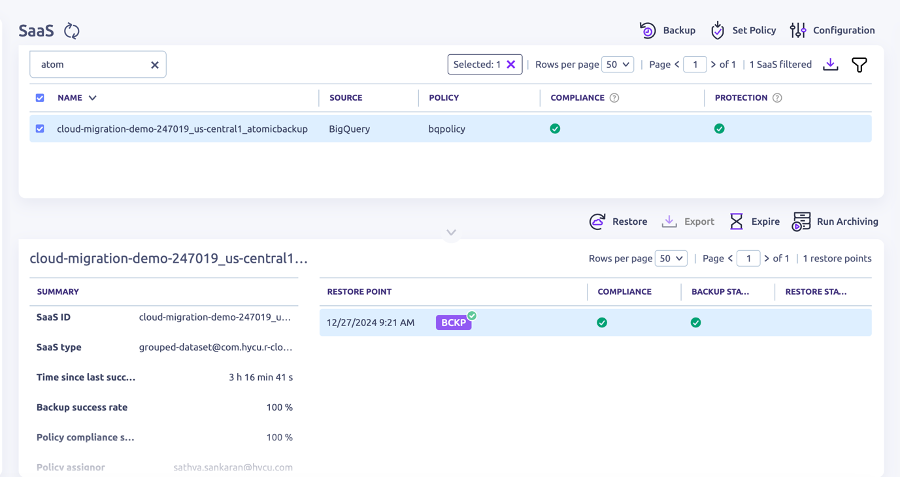
Récupération des ensembles de données BigQuery
Vos options de récupération restent flexibles. Vous pouvez continuer à restaurer des ensembles de données et des tables individuels, dans le même projet ou dans un projet différent portant le même nom ou un nouveau nom. Tout ensemble de données faisant partie de l'ensemble de sauvegarde atomique aura des points de récupération qui ont été protégés au même moment. Lorsque vous restaurez des ensembles de données, les vues et les routines sont également restaurées.
Conclusion
L'introduction par HYCU des ensembles de sauvegarde atomiques dans les exportations BigQuery constitue une avancée significative dans la gestion des données. En tirant parti des groupes de cohérence et des sauvegardes atomiques, vous pouvez vous assurer que vos ensembles de données BigQuery sont cohérents, fiables et plus faciles à gérer. Que vous traitiez des analyses de données à grande échelle, des tendances, de l'exploration sur des données historiques, ou que vous ayez simplement besoin de maintenir l'intégrité des données, les ensembles de sauvegarde atomique fournissent une solution robuste pour répondre à vos besoins.
Les ensembles de sauvegarde atomique constituent une solution robuste pour répondre à vos besoins.



Obtenez les dernières informations et mises à jour
By submitting, I agree to the HYCU Subscription Agreement , Terms of Usage , and Privacy Policy .