Sauvegarde et reprise après sinistre de BigQuery (restauration granulaire automatisée)

Qu'est-ce que BigQuery?
BigQuery est un entrepôt de données de niveau entreprise doté d'une architecture sans serveur qui permet aux utilisateurs d'exécuter des requêtes de type SQL sur de grands ensembles de données en utilisant la puissance de traitement de l'infrastructure de Google.
En tant que solution entièrement gérée, BigQuery dispose de fonctionnalités intégrées telles que l'apprentissage automatique, la veille stratégique, l'analyse en temps réel et même l'analyse géospatiale, qui aident les entreprises modernes cherchant à exploiter de grandes quantités de données dans leur processus de prise de décision. Cela est particulièrement dû à sa capacité à traiter des téraoctets de données en quelques secondes et des pétaoctets en quelques minutes, ce qui en fait un outil parfait pour l'analyse de données à grande échelle.
Important, BigQuery est sans serveur. Cela signifie qu'aucune gestion d'infrastructure n'est nécessaire, ce qui vous permet de vous concentrer sur l'analyse de données importantes pour obtenir des informations significatives au lieu de vous préoccuper des frais généraux.
Importance de BigQuery dans l'analyse et l'entreposage des données
Le concept de " big data " (volume, vitesse et variété) pose un défi de taille aux capacités de traitement des données des systèmes traditionnels. Cela est précisément dû à leur capacité, leur évolutivité et leur puissance de traitement limitées, ce qui rend l'extraction d'informations significatives à partir d'ensembles de données vastes et complexes presque impossible et prend du temps.
En outre, BigQuery occupe également une position vitale en raison de ses avantages uniques, tels que :
- Un modèle sans serveur qui aide à simplifier les opérations.
- Ses capacités à grande vitesse rendent possible l'insertion de milliers de lignes de données par seconde, ce qui permet des analyses en temps réel.
- Son infrastructure sous-jacente assure une haute disponibilité, ce qui facilite la mise à l'échelle automatique pour s'adapter à de grands ensembles de données.pay-as-you-go" facilite également la gestion des capacités et des coûts CAPEX, en particulier pour l'infrastructure, telle que les serveurs, les centres de données et d'autres matériels.
La nécessité d'une sauvegarde et d'une restauration de BigQuery
Malgré toutes ses fonctions et capacités puissantes, les données de BigQuery, comme toutes les autres " données numériques ", sont vulnérables à la suppression accidentelle, à la perte ou à la corruption.
Exemple réel de perte de données BigQuery
Mettons qu'une entreprise utilise BigQuery pour ses besoins en matière d'entreposage de données.
- Elle stocke une pléthore de données, notamment des enregistrements de ventes, des informations sur les clients et des détails sur les produits.
- Un jour, un employé peut être chargé d'éliminer les enregistrements périmés du système pour maintenir l'efficacité du stockage.
- Ils exécutent donc une commande, avec l'intention de supprimer les données datant de plus de cinq ans.
Cependant, en raison d'une erreur dans la commande SQL, le système interprète mal le critère de suppression et tous les enregistrements de plus d'un an sont supprimés.
Si la suppression passe inaperçue et qu'un autre employé tente d'effectuer une analyse des tendances sur plusieurs années, il lui sera impossible de le faire car une année entière de données est manquante. Sans une stratégie de sauvegarde solide, la récupération de ces données n'est pas garantie.
Dans ce scénario, malgré la fiabilité de BigQuery, les données qu'il contient étaient vulnérables à l'erreur humaine - une suppression accidentelle dans ce cas. Cela peut également s'appliquer dans des scénarios impliquant la conformité réglementaire et les exigences de conservation des données pour certaines organisations.
Pour protéger vos informations précieuses, il est crucial d'avoir une stratégie de sauvegarde robuste qui garantit que vous pouvez rapidement récupérer de tout problème imprévu lié aux données et maintenir la continuité de vos activités.
Utilisation de HYCU pour la sauvegarde de Google BigQuery
Quand il s'agit de protéger vos données sur Google BigQuery, HYCU offre une solution complète et facile à utiliser.
- En cas de perte de données ou de défaillance du système, HYCU permet de restaurer instantanément vos tables et leurs états antérieurs. Ainsi, le temps d'arrêt et l'interruption des activités sont réduits au minimum.
- Un autre avantage et superpuissance de HYCU est son processus de récupération précis et fiable pour Google Cloud. HYCU garantit que les données restaurées conservent leur intégrité et leur cohérence, en reproduisant l'état des données au moment de la sauvegarde. Cela est particulièrement crucial pour les charges de travail analytiques ou complexes sur BigQuery, où l'exactitude et la cohérence des données sont primordiales.
Restaurer des tables et des ensembles de données en quelques clics

Automatisez toutes les opérations de sauvegarde en 1 clic
HYCU automatise la sauvegarde de vos ensembles de données, tables et schémas BigQuery, éliminant ainsi le besoin d'intervention manuelle. Cela vous libère du temps et réduit considérablement le risque d'erreur humaine (par exemple, une mauvaise utilisation de la souris entraînant une suppression accidentelle) conduisant à une perte de données.
En outre, HYCU offre la possibilité de personnaliser les paramètres de sauvegarde :
- Planifier les sauvegardes pendant les heures creuses pour minimiser l'impact sur les performances.
- Définir des politiques de conservation pour la conformité réglementaire.
- Choisir les emplacements de stockage des sauvegardes pour la souveraineté des données.
Et toutes ces sauvegardes sont cryptées pendant le transport et au repos, ce qui garantit la sécurité de vos données.
Sauvegardes natives de Google Cloud sans calcul
HYCU est nativement conçu pour fonctionner avec les API de Google, et les clients n'ont pas besoin d'utiliser un script pour effectuer des configurations pour les opérations de sauvegarde traditionnelles.
En outre, vous pouvez configurer HYCU pour sauvegarder vos données BigQuery sur Google Cloud Storage (GCS) pour une conservation des données à long terme. Cette flexibilité garantit que vos données sauvegardées peuvent être facilement utilisées ou migrées en fonction de vos cas d'utilisation ou exigences spécifiques.
Au-delà de BigQuery : protégez votre infrastructure Google Cloud
HYCU fournit des sauvegardes automatisées et une restauration granulaire à travers l'infrastructure Google Cloud, DBaaS, PaaS et SaaS. En fait, HYCU se targue d'offrir la couverture la plus complète de l'infrastructure et des services Google Cloud, avec une prise en charge complète :
- Google Cloud Engine (GCE)
- Google Cloud Storage
- Google CloudSQL
- Google BigQuery
- Google Kubernetes Engine (GKE)
- Google Cloud VMware Engine
- Google Workspace
- SAP HANA dans Google Cloud
Protégez l'infrastructure multicloud, PaaS, DBaaS et SaaS
HYCU ne se limite pas à la sauvegarde de vos données BigQuery ; Il prend également en charge diverses sources de données et charges de travail. Cela signifie que, que vous ayez d'autres charges de travail dans Google, d'autres clouds publics, des centres de données sur site, ou même des applications SaaS, DBaaS et PaaS, HYCU peut les sauvegarder et les restaurer de manière transparente.
De l'autre côté, spécifiquement pour BigQuery, HYCU fournit une protection complète des données. Cela garantit que toutes vos données BigQuery, y compris les tables et les schémas individuels, peuvent être restaurées.
💡 Related → Top 14 SaaS Backup Solutions & Tools for SaaS Data Protection
Souscrivez et protégez en quelques clics
L'une des principales caractéristiques de HYCU est son interface conviviale et sa documentation complète, La mise en place et la configuration de vos sauvegardes BigQuery se font sans effort.
Par exemple, HYCU simplifie les opérations de sauvegarde en découvrant automatiquement toutes les instances et charges de travail de votre compte, ce qui vous permet d'attribuer des politiques pré-packagées en un clic ou de créer les vôtres.
Notamment, ces politiques sont "définies et oubliées", ce qui signifie qu'elles fonctionnent 24 heures sur 24, 7 jours sur 7 et 365 jours par an, sans aucune opération manuelle ni gestion quotidienne.
Protection des données et sécurité renforcées
En plus d'hériter automatiquement des rôles et autorisations de Google Cloud IAM (Identity and Access Management), HYCU propose également une fonction de contrôle d'accès basé sur les rôles (RBAC).
Cette fonction vous permet de définir les droits d'accès et les rôles pour les opérations de sauvegarde et de restauration. Cette intégration garantit que les opérations de sauvegarde et de restauration ne sont effectuées que par des utilisateurs autorisés.
Tarification rentable
HYCU offre des options de tarification flexibles, garantissant que les entreprises de toutes tailles bénéficient de ses capacités de sauvegarde robustes. Le coût de l'utilisation de HYCU s'adapte à vos besoins spécifiques, tels que la quantité de données à sauvegarder, la fréquence des sauvegardes et la période de conservation requise. Cette approche vous permet d'adapter le service à vos besoins et de ne payer que ce dont vous avez besoin.
Une vue unique de votre parc Google avec état de protection
Si votre entreprise est comme la plupart des autres, il se peut que vous utilisiez beaucoup plus de services Google, ainsi que d'autres services de cloud public et applications SaaS. Cela représente un énorme défi en termes de suivi, sans parler de la garantie que les données et la configuration sont protégées et disponibles pour la restauration. Avec R-Graph, les utilisateurs de HYCU peuvent suivre l'ensemble de l'infrastructure et des services en nuage, PaaS, DBaaS et SaaS dans une seule vue "carte au trésor". Vous serez en mesure de savoir quels services sont protégés et conformes et lesquels nécessitent une protection.
💡 Related → Google Workspace (G Suite) Backup & Recovery Solution
Options et configurations par défaut de BigQuery Backup
Pour activer BigQuery Backup, vous devez disposer d'un accès administrateur avec les rôles IAM suivants pour gérer les ensembles de données :
- Copier un jeu de données (Beta):
- BigQuery Admin (roles/bigquery.admin) sur le projet de destination
- BigQuery Data Viewer (roles/bigquery.dataViewer) sur le jeu de données source
- BigQuery Data Editor (roles/bigquery.dataEditor) sur le jeu de données de destination
- Supprimer un jeu de données : Propriétaire de données BigQuery (roles/bigquery.dataOwner) sur le projet
- Restaurer un jeu de données supprimé : BigQuery Admin (roles/bigquery.admin) sur le projet
Une fois que vous avez l'accès, vous pouvez gérer les configurations et les options de sauvegarde ci-dessous.
Sauvegardes au niveau du jeu de données de copie
Un jeu de données typique dans BigQuery est un conteneur de premier niveau qui héberge vos tables et vos vues. C'est également un moyen efficace d'organiser et de contrôler l'accès à vos données. Par exemple, en séparant les données brutes des données traitées ou des données provenant de différents départements ou projets.
En revanche, la configuration des sauvegardes au niveau du jeu de données implique la création et l'exportation d'une copie de vos données vers un emplacement spécifique, par exemple un godet de stockage en nuage. Cette action garantit la disponibilité et l'intégrité de vos données, même en cas de suppression ou de modification accidentelle.
Méthodes de configuration des sauvegardes au niveau des jeux de données
Il existe deux méthodes de configuration des sauvegardes au niveau des jeux de données : l'API BigQuery et les commandes SQL.
Utilisation de l'API BigQuery
L'API BigQuery vous permet d'utiliser le service de transfert de données BigQuery pour planifier des transferts de données automatisés à partir de BigQuery pour un seau de stockage Cloud.
- Comme les sauvegardes seront stockées dans le seau Google Cloud Storage, créez un nouveau seau dans la section "Storage" de la Cloud Console.
- Accédez à la bibliothèque API et activer l'API BigQuery Data Transfer Service et Cloud Storage API.
- Choisissez un langage de programmation et installez la bibliothèque client correspondante pour l'API BigQuery. Lisez la documentation ici.
- Installez le Google Cloud SDK. Il fournit l'outil de ligne de commande nécessaire pour interagir avec les API et les autres services Google Cloud.
- Authenticatez le SDK avec votre compte Google Cloud à l'aide des commandes de la gCLI. Cela garantit que le SDK peut accéder à votre compte et effectuer des opérations en votre nom.
- Si vous n'en avez pas déjà un, créez un nouveau jeu de données.
- Définissez la configuration. Spécifiez l'ensemble de données, le projet, les identifiants de table et le Cloud Storage Bucket.
- Exportez les données de vos tables BigQuery vers un Cloud Storage bucket en effectuant une demande auprès de l'API.
Une fois le processus confirmé, assurez-vous que votre jeu de données BigQuery et votre Cloud Storage se trouvent à l'emplacement exact afin d'éviter tout problème potentiel.
💡Note → Cette option de sauvegarde BigQuery n'est qu'une copie des données existantes et non une incrémentation.
Recommandé → En savoir plus sur les Google Cloud APIs
Utilisation des commandes SQL
Les commandes SQL dans BigQuery offrent une autre option pour gérer et interagir avec les ensembles de données. Dans le contexte de la Sauvegarde des données, cela n'est pas entièrement possible - il en va de même pour toutes les options de sauvegarde de BigQuery. Au lieu de cela, il s'agit de créer une nouvelle table avec des données existantes.
Recommandé → Lisez la documentation de Google sur la création d'ensembles de données à l'aide de commandes SQL.
💡Note: Il ne s'agit pas précisément d'une solution de sauvegarde ; vous créez plutôt des ensembles de données à un autre endroit.
Outre la mise en place de ces configurations de sauvegarde dans BigQuery, vous devez tenir compte de certains paramètres clés :
- Fréquence de sauvegarde. Cela dépend entièrement de la fréquence des modifications de vos données. Si vos données changent rapidement, vous aurez peut-être besoin de sauvegardes quotidiennes ou horaires. Si ce n'est pas le cas, vous pouvez choisir une fréquence mensuelle ou hebdomadaire.
- Politiques de conservation. Elles peuvent être définies en fonction des besoins de votre entreprise, pour autant qu'elles soient conformes aux lois sur les données qui régissent votre secteur d'activité.
- Schema Preservation. Cet aspect essentiel de la configuration garantit que le schéma (ou la structure) de vos données reste intact. Cela signifie que tous les types de données, noms, tables et autres informations pertinentes sont exacts, même pendant la réplication.
Capture au niveau de la table
La sauvegarde au niveau de la table dans BigQuery vous permet de sélectionner des tables individuelles au sein d'un ensemble de données pour les sauvegarder. Cette fonction est particulièrement utile dans les scénarios où seules certaines tables de l'ensemble de données doivent être sauvegardées.
Création d'instantanés pour des tables individuelles.
Il existe deux méthodes standard pour créer des instantanés pour des tables individuelles ;
- Vous pouvez utiliser la commande 'bq extract' via l'outil de ligne de commande, OU
- Vous pouvez utiliser l'API BigQuery pour faire une demande.
Voici un exemple :
bq extract 'my_dataset.my_table' gs://my_bucket/my_table_backup
Où :
- 'my_dataset.my_table' est la table que vous souhaitez sauvegarder - et,
- 'gs://my_bucket/my_table_backup' est l'emplacement GCS où la sauvegarde sera stockée.
Les deux méthodes exporteront les données de la table sous forme de fichiers au format de votre choix vers le seau Google Cloud Storage (GCS), ce qui facilitera l'importation et la restauration de la table si nécessaire.
Le GCS est une option préférable pour le stockage de vos sauvegardes de tables BigQuery en raison de sa sécurité, de sa fiabilité et de son rapport coût-efficacité.
Exporter vos sauvegardes de tables BigQuery dans différents formats.
Vous pouvez exporter les données de vos tables dans les formats suivants :
- JSON (Javascript Object Notation). Il s'agit d'un format flexible et lisible par l'homme, qui est donc plus facile à comprendre et à utiliser. Toutefois, il peut être plus volumineux (en taille) et plus lent que d'autres formats.
- CSV (Comma-Separated Values). Il s'agit d'un format simple et largement supporté pour la plupart des scénarios de représentation de données sous forme de tableaux. Cependant, il ne présente pas avec précision les structures de données complexes.
- Avro est un cadre de sérialisation de données orienté ligne. Son format binaire compact le rend idéal pour traiter les grands ensembles de données, en particulier lorsque le schéma de la table change au fil du temps. En outre, vous pouvez compresser les fichiers stockés au format Avro, ce qui réduit le temps de stockage et accélère la sauvegarde/restauration.
- Parquet (Apache Parquet) est un format de stockage de données orienté colonnes. Il peut également gérer de grands ensembles de données et offre d'excellentes capacités de compression. Toutefois, il peut présenter certaines limites en ce qui concerne les mises à jour fréquentes des tables.
Gestion des tables BigQuery partitionnées et des sauvegardes incrémentielles
Le partitionnement des tables dans BigQuery est une approche de la gestion et de l'organisation des grands ensembles de données.
Idéalement, vous devriez effectuer une sauvegarde basée sur la stratégie de partition existante.
Pour cela, vous pouvez soit :
- sauvegarder la table entière, y compris toutes les partitions, OU
- ou sauvegarder des partitions spécifiques.
Toutefois, l'exportation des seules partitions modifiées ou nouvellement ajoutées est plus efficace en termes de stockage si vous avez affaire à des sauvegardes incrémentielles.
Par exemple, si votre table est partitionnée par date, vous ne pouvez extraire que la partition d'aujourd'hui.
Limitations des instantanés de table
- Un instantané de table doit se trouver dans la même région et sous la même organisation que sa table de base.
- Les instantanés de table sont en lecture seule. Vous ne pouvez pas mettre à jour les données d'un instantané de table à moins de créer une table standard à partir de l'instantané, puis de mettre à jour les données. Vous ne pouvez mettre à jour que les métadonnées d'un instantané de table, par exemple sa description, sa date d'expiration et sa politique d'accès.
- Vous ne pouvez prendre un instantané des données d'une table qu'il y a sept jours ou plus récemment en raison de la limite de sept jours pour les déplacements dans le temps.
- Vous ne pouvez pas prendre un instantané d'une table externe.
- Vous ne pouvez pas écraser une table existante ou un instantané de table lorsque vous créez un instantané de table.
- Si vous effectuez un instantané d'une table dont les données se trouvent dans un stockage optimisé en écriture (tampon de streaming), les données du stockage optimisé en écriture ne sont pas incluses dans l'instantané de table.
- Si vous effectuez un instantané d'une table dont les données sont en déplacement dans le temps, les données en déplacement dans le temps ne sont pas incluses dans l'instantané de table.
- Si vous effectuez un instantané d'une table partitionnée dont l'expiration de la partition est définie, les informations relatives à l'expiration de la partition ne sont pas conservées dans l'instantané. La table 'snapshotted' utilise l'expiration de partition par défaut de l'ensemble de données de destination. Pour conserver les informations relatives à l'expiration de la partition, copiez plutôt la table.
- Vous ne pouvez pas copier un instantané de table.
Sauvegardes basées sur des instantanés
Un instantané dans BigQuery est une copie ponctuelle des données d'une table (appelée table de base). Cela signifie qu'il capture l'état de la table et de ses données à un moment précis, ce qui vous permet de restaurer à partir de ce point précis si nécessaire.
En d'autres termes, il s'agit de prendre une photo de vos données. Et cela peut s'avérer précieux dans des cas tels que la conformité, l'audit ou l'analyse des tendances, où cela fournit une vue cohérente des données telles qu'elles existaient à un moment donné.
💡Note → Les instantanés de table sont en "lecture seule", mais vous pouvez créer/restaurer une table standard à partir d'un instantané, puis la modifier.
Création et gestion d'instantanés pour la restauration ponctuelle
Vous pouvez créer un instantané d'une table à l'aide des options suivantes :
- Google Cloud Console
- Instruction SQL
- La commande
bq cp --snapshot - jobs.insert API
Par exemple, si vous utilisez Google Cloud Console, procédez comme suit :
- Accédez à la Cloud Console, et naviguez jusqu'à la page BigQuery.
- Retrouvez le volet 'Explorateur', et développez les nœuds de projet et de jeu de données de la table que vous souhaitez snapshoter.
- Cliquez sur le nom de la table et cliquez sur 'SNAPSHOT.'

- Une fenêtre "Créer un instantané de table" s'affichera ensuite. Saisissez les informations Projet, Table et Dataset pour le nouvel instantané de table.
- Sélectionnez votre heure d'expiration.
- Cliquez sur Save.
Une fois que vous avez créé cet instantané, il est détaché de la table d'origine. Cela signifie que toute modification apportée à la table n'affectera pas les données de l'instantané dans la nouvelle table.
Recommandé → En savoir plus sur la création d'instantanés de table à l'aide d'autres options.
Avantages des sauvegardes basées sur des instantanés
- Data versioning. Cela vous permet d'accéder aux données telles qu'elles sont apparues à des moments précis. Vous pouvez ainsi retracer les modifications ou restaurer les données à leur état d'origine si nécessaire.
- Analyse historique. Vous pouvez comparer différents instantanés pour suivre l'évolution des données dans le temps. Cela peut vous aider à comprendre les tendances et à améliorer votre processus de prise de décision.
- Rétention des données. Certaines industries et organisations ont des politiques strictes de conservation des données pour se conformer aux exigences réglementaires. Les sauvegardes basées sur des instantanés vous permettent de conserver les données pendant une durée spécifique, conformément à la réglementation.
Utiliser la fonction de voyage dans le temps de BigQuery pour la restauration des données
BigQuery offre une fonction appelée "time travel", qui vous permet d'accéder aux versions historiques de votre table au cours des sept derniers jours.
Avec la fonction de voyage dans le temps, vous pouvez restaurer ou préserver les données d'une table à partir d'une date spécifique, en annulant toutes les modifications effectuées après cette date choisie.
Les sauvegardes basées sur des instantanés et la fonction de voyage dans le temps renforcent considérablement votre stratégie de protection des données dans BigQuery.
Notez que le "voyage dans le temps" n'est pas une solution de récupération garantie en cas de défaillance opérationnelle, de cyberattaque ou de catastrophe naturelle.
Voici pourquoi :
- Le délai de récupération des données est limité à sept jours. Si un problème n'est pas détecté dans ce délai, les données ne peuvent pas être récupérées.
- Time travel n'offre pas la possibilité de dupliquer ou de sauvegarder vos données. Il vous permet simplement de revenir à l'état antérieur de vos données.
De ce fait, il devient essentiel d'employer d'autres mesures de sauvegarde telles que des exportations régulières de données vers Google Cloud Storage et la réplication des données pour garantir une sécurité complète des données.
Mise en œuvre des solutions de sauvegarde BigQuery
Utilisation de Python et de GitHub
Avec sa facilité d'utilisation et son vaste support de bibliothèque, Python facilite l'interaction avec BigQuery et l'automatisation de l'ensemble du processus de sauvegarde.
Maintenant, en utilisant Python avec GitHub, une plateforme de premier plan pour l'hébergement et le contrôle de version du code, vous pouvez gérer vos scripts, suivre les modifications - et même collaborer avec d'autres.
Pour que cela fonctionne, vous devez exploiter les bibliothèques et dépôts Python existants afin de rationaliser votre processus de développement :
- google-cloud-bigquery. Cette bibliothèque Python officielle provient de Google Cloud et offre des fonctionnalités telles que la gestion des ensembles de données, la planification et l'exécution des requêtes.
Voici un exemple d'utilisation de Python pour effectuer une requête
from google.cloud import bigquery.
client = bigquery.Client()
# Effectuez une requête.
QUERY = (
'SELECT name FROM `bigquery-public-data.usa_names.usa_1910_2013` '
'WHERE state = "TX" '
'LIMIT 100')
query_job = client.query(QUERY) # requête API
rows = query_job.result() # Attend la fin de la requête
for row in rows :
print(row.name)- google-cloud-storage. Cette bibliothèque permet d'automatiser le stockage de vos sauvegardes dans Google Cloud.
- pandas-gbq. Cette bibliothèque fait le lien entre BigQuery et Pandas. Elle simplifie la récupération des résultats des tables BigQuery à l'aide de requêtes de type SQL.
Exemples de ce que vous pouvez faire avec la bibliothèque pandas-gbq :
Exécuter une requête :
import pandas_gbqresult_dataframe = pandas_gbq.read_gbq("SELECT column FROM dataset.table WHERE value = 'something'")
Téléchargement d'un dataframe:
import pandas_gbq
pandas_gbq.to_gbq(dataframe, "dataset.table")
En outre, le respect de certaines bonnes pratiques standard est crucial lorsque vous utilisez Python et GitHub pour créer des sauvegardes BigQuery.
- Surveillez vos travaux de sauvegarde. Implémentez la gestion des erreurs et la journalisation dans vos scripts pour déclencher un système d'alerte qui vous notifie des problèmes potentiels avec le processus de sauvegarde.
- Modularisez vos scripts Python. La modularisation est simplement un moyen d'organiser les programmes à mesure qu'ils se compliquent. Dans ce cas, divisez vos fonctions liées à la sauvegarde en modèles réutilisables, ce qui facilitera leur gestion et leur maintenance au fur et à mesure de leur développement.
- Utiliser des fichiers de configuration. Également appelés "fichiers de configuration,", ils sont utilisés pour stocker les paires clé-valeur d'un code Python. Par exemple, lorsque vous exécutez des sauvegardes BigQuery, vous pouvez utiliser un fichier de configuration pour stocker les identifiants de projet, les noms des jeux de données et les emplacements de sauvegarde. Cela permet de modifier facilement le code sans l'altérer.
Utilisation de la ligne de commande et du SDK Google Cloud
La ligne de commande (ou gCLI) est un ensemble d'outils utilisés pour gérer les applications et les ressources hébergées sur Google Cloud. Ces outils comprennent les outils de ligne de commande gcloud, gsutil et bq. Par exemple, vous pouvez planifier et automatiser toutes les tâches liées à la sauvegarde à l'aide de la ligne de commande.
D'autre part, le SDK Google Cloud facilite le développement et l'interaction avec l'API Google Cloud à l'aide de votre langage de programmation préféré.
Combinez les deux, et vous pourrez gérer facilement vos sauvegardes BigQuery.
Comment configurer votre SDK Google Cloud.
- Rendez-vous sur Cloud SDK - Libraries and Command Line Tools | Google Cloud.
- Téléchargez le package d'installation de votre machine respective (Windows, macOS, Ubuntu et Linux) et suivez les instructions de la page.
- Installez le Google Cloud SDK à l'aide de la commande './google-cloud-sdk/install.sh' et suivez les invites nécessaires.
- Authenticatez votre compte pour activer les ressources BigQuery à l'aide de la ligne de commande 'gcloud auth login'.
Maintenant que votre SDK Google Cloud est configuré, la prochaine étape consiste à utiliser la ligne de commande pour effectuer diverses fonctions de sauvegarde.
Créer des sauvegardes
Créer une sauvegarde BigQuery en utilisant la ligne de commande '[bq cp]' revient simplement à copier la table d'un emplacement à un autre. Les emplacements peuvent être à travers différents projets, différents ensembles de données, ou même au sein des mêmes ensembles de données.
bq cp [project_id] :[dataset].[table] [project_id] :[backup_dataset].[backup_table]
Où votre ;
- '[project_id]' est votre identifiant Google Cloud.
- '[dataset]' contient la table que vous souhaitez sauvegarder.
- '[table]' contient le nom de la table que vous souhaitez sauvegarder.
- '[backup_dataset]' est le dataset dans lequel vous souhaitez stocker la sauvegarde.
- '[backup_table]' est le nom de la table de sauvegarde.
Exporter des données
Vous utilisez la ligne de commande '[bq extract]' pour exporter des données de BigQuery vers Google Cloud Storage ou des systèmes de stockage externes. Cette ligne de commande permet également d'exporter des données en JSON, CSV, Avro et Parquet.
bq extract --destination_format=[format] [project_id] :[dataset].[table] gs://[bucket]/[path]
Ici, remplacez;
- '[format]' par le format d'exportation de votre choix.
- '[bucket]' par le nom de votre bucket Google Cloud Storage.
- '[path]' par le chemin dans lequel vous souhaitez stocker les données exportées.
Par exemple :
bq extract --destination_format CSV 'mydataset.mytable' gs://mybucket/mydata.csv
Gérer les sauvegardes
Pour gérer vos sauvegardes BigQuery, vous utilisez la commande [bq ls]'pour lister toutes les sauvegardes [ou table] dans un jeu de données spécifique - ou [bq rm]'pour supprimer une table.
bq ls mydatasetbq rm 'mydataset.mytable'
Limitations des options de sauvegarde BigQuery
Option de récupération ponctuelle limitée
Supposons que vous ayez un jeu de données critique dans BigQuery qui subit des mises à jour et des transformations fréquentes. Un jour, l'ensemble de données devient inexact en raison d'un problème de corruption de données.
Dans la mesure où BigQuery n'offre pas de récupération ponctuelle, vous ne pouvez pas facilement restaurer l'ensemble de données à un état antérieur à la corruption. Sans sauvegardes automatisées, vous devrez peut-être vous appuyer sur des exportations manuelles ou des instantanés que vous avez pris précédemment, ce qui pourrait prendre du temps et être potentiellement obsolète.
Processus d'importation et d'exportation complexe
Disons que vous avez un grand ensemble de données dans BigQuery et que vous souhaitez créer une sauvegarde dans un système de stockage externe, tel que Google Cloud Storage (GCS) ; bien que BigQuery permette d'exporter des données dans des formats tels qu'Avro, Parquet ou CSV, l'exportation de grands ensembles de données peut s'avérer complexe et gourmande en ressources.
Par exemple, l'exportation de plusieurs téraoctets de données vers GCS peut nécessiter un temps et des ressources réseau considérables, entraînant des coûts supplémentaires et des perturbations potentielles des opérations en cours.
Pauvre politique de conservation des sauvegardes
Par défaut, BigQuery conserve les tables ou les ensembles de données supprimés dans la "Trash" pendant 30 jours avant de les supprimer définitivement. Bien que cela offre un certain niveau de protection contre les suppressions accidentelles, vous ne pouvez pas prolonger ou personnaliser cette période de rétention.
Scripts et configuration gourmands en ressources
La gestion des scripts et des configurations personnalisées peut s'avérer complexe, en particulier lorsque l'environnement évolue. La gestion des scripts peut être décourageante et prendre beaucoup de temps pour un service comme BigQuery, sans parler de la gestion de plusieurs services en nuage.
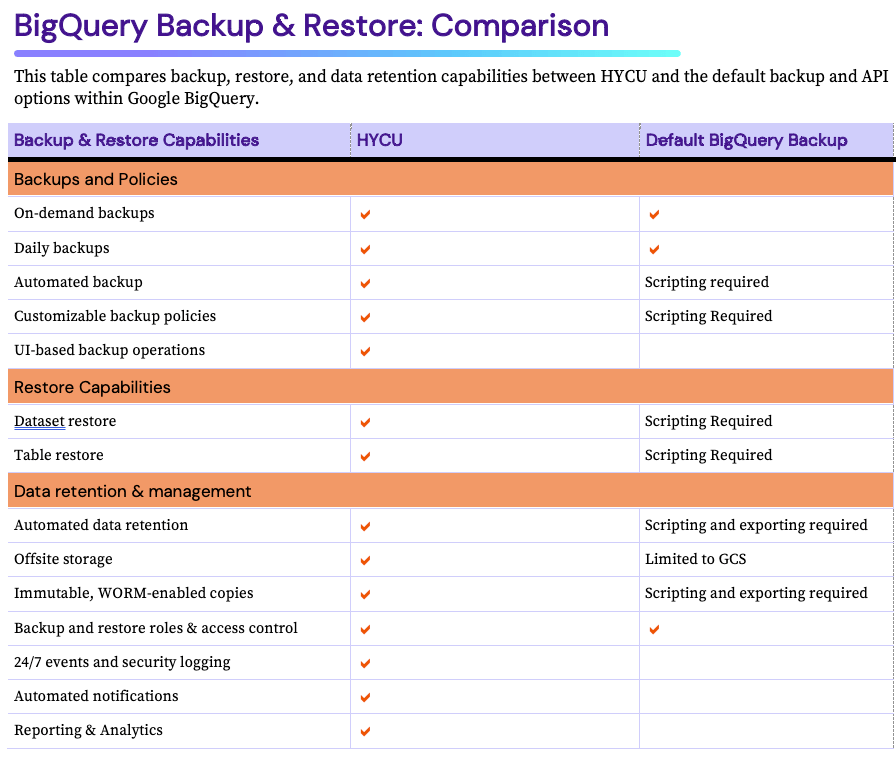
Sauvegarde et restauration BigQuery : Le bilan
Google BigQuery est sans aucun doute un outil puissant pour les organisations axées sur les données. Ses requêtes SQL rapides comme l'éclair, ses capacités d'apprentissage automatique intégrées et son infrastructure évolutive en font une solution fiable, en particulier pour le traitement de grandes quantités de données. Cependant, le schéma, les ensembles de données et les tables de valeur résidant dans BigQuery doivent être protégés pour atténuer les risques de perte de données ou de défaillance du système. C'est là que HYCU vient vous sauver la mise.
Avec HYCU Protégé, vous bénéficiez de sauvegardes en 1 clic et d'une restauration granulaire pour vos données BigQuery. Cette sauvegarde automatisée "set and forget" fonctionne 24/7/365, vous offrant une tranquillité d'esprit totale que vos données BigQuery seront disponibles en cas de besoin.
Vous avez besoin d'une sauvegarde et d'une restauration cloud-native pour Google BigQuery ?



Obtenez les dernières informations et mises à jour
By submitting, I agree to the HYCU Subscription Agreement , Terms of Usage , and Privacy Policy .