
BigQueryとは
BigQueryは、サーバーレスアーキテクチャを備えたエンタープライズレベルのデータウェアハウスで、ユーザーはGoogleのインフラストラクチャの処理能力を使用して、大規模なデータセットに対してSQLライクなクエリを実行できます。
完全に管理されたソリューションであるBigQueryには、機械学習、ビジネスインテリジェンス、リアルタイム分析、さらには地理空間分析などの機能が組み込まれており、意思決定プロセスで膨大な量のデータを活用したいと考えている現代の企業を支援します。これは特に、テラバイト単位のデータを数秒で、ペタバイト単位のデータを数分で実行できる機能によるもので、大規模なデータ分析に最適なツールとなっています。
重要なのは、BigQueryがサーバーレスであるということです。つまり、インフラ管理が不要なため、オーバーヘッドを気にする代わりに、重要なデータを分析して意味のある洞察を得ることに集中しやすくなります。
データ分析とウェアハウスにおけるBigQueryの重要性
「ビッグデータ」(量、速度、多様性)という概念は、従来のシステムのデータ処理能力に大きな課題を突きつけています。これはまさに、容量、スケーラビリティ、処理能力に限界があるためであり、膨大で複雑なデータセットから意味のある洞察を抽出することはほぼ不可能で、時間もかかります。
幸いなことに、ここでBigQueryの出番です。BigQueryの堅牢なアーキテクチャにより、構造化データおよび半構造化データを使用した機械学習モデルの作成、トレーニング、デプロイがBigQuery上で行えるようになり、洞察の抽出プロセスが効率化されます。
さらに、BigQueryは次のような独自の利点により、重要な地位を占めています:
- 運用の簡素化を支援するサーバーレスモデル
- 高速機能により、1秒間に数千行のデータを挿入することが可能で、リアルタイムの分析が可能
- 基盤となるインフラストラクチャが高可用性を保証し、大規模なデータセットに対応するための自動スケーリングが容易です。
- 堅牢なデータセキュリティを保証し、Data Studio、Looker、Tableauなどの他のツールやサービスとシームレスに統合します。
- また、「pay-as-you-go 」モデルでは、特にサーバー、データセンター、その他のハードウェアなどのインフラストラクチャにおいて、企業が容量とCAPEXコストを管理しやすくなっています。
BigQueryのバックアップと復元の必要性
BigQueryのデータは、その強力な機能と性能にもかかわらず、他の「デジタルデータ」と同様に、誤って削除したり、紛失したり、破損したりする可能性があります。
BigQueryデータ損失の実例
ある企業がデータウェアハウスのニーズにBigQueryを利用しているとしましょう。
- 販売記録、顧客情報、製品詳細など、多くのデータが保存されています。
- ある日、従業員は、ストレージの効率を維持するために、システムから古いレコードを削除することを命じられるかもしれません。
- そこで従業員は、5年以上前のデータを削除するつもりで、コマンドを実行します。
しかし、SQLコマンドのエラーにより、システムは削除基準を誤って解釈し、1年以上前のレコードがすべて削除されました。
削除に気づかず、別の従業員が複数年の傾向分析を実行しようとした場合、1年分のデータが欠落しているため不可能です。堅牢なバックアップ戦略がなければ、このデータの回復は保証されません。
このシナリオでは、BigQueryの信頼性にもかかわらず、BigQuery内のデータは人為的なミス(この場合は誤って削除)に対して脆弱でした。これは、組織によっては、規制コンプライアンスやデータ保持要件に関わるシナリオにも当てはまります。
貴重な情報を保護するためには、 堅牢なバックアップ戦略を持つことが非常に重要です。
Google BigQueryのバックアップにHYCUを使用する
Google BigQueryのデータ保護に関しては、HYCUは包括的で使いやすいソリューションを提供します。
- データ損失やシステム障害が発生した場合、HYCUは即座にテーブルと以前の状態を復元する機能を提供します。
- Google Cloudのための正確で信頼性の高いリカバリプロセスもHYCUの利点であり強みです。HYCUは、バックアップ時のデータの状態をミラーリングすることで、復元されたデータの整合性と一貫性を維持することを保証します。これは、データの正確性と一貫性が最も重要であるBigQuery上の分析ワークロードや複雑なワークロードにとって特に重要です。
数クリックでテーブルとデータセットを復元

1 クリックですべてのバックアップ操作を自動化
HYCU は、BigQuery のデータセット、テーブル、スキーマのバックアップを自動化し、手動による操作を不要にします。これにより、作業時間が短縮され、人為的なミス(マウスの誤操作による偶発的な削除など)によるデータ損失のリスクが劇的に軽減されます。
さらに、HYCUはバックアップ設定をカスタマイズする機能を提供しています。
- ピーク時を避けてバックアップをスケジュールし、パフォーマンスへの影響を最小限に抑える
- 規制遵守のための保存ポリシーを設定する
- データの主権を守るためにバックアップの保存場所を選択する
また、これらのバックアップはすべて、転送中および保存時に暗号化され、データのセキュリティを確保します。
HYCUはGoogle APIで動作するようにネイティブに構築されており、従来のバックアップ操作のためにスクリプトを使用して設定を実行する必要はありません。
さらに、BigQueryデータをGoogle Cloud Storage (GCS)にバックアップするようにHYCUを設定し、長期的にデータを保持することができます。この柔軟性により、バックアップされたデータは、特定のユースケースや要件に応じて、すぐに利用または移行できるようになります。
BigQueryを超えて:Google Cloudインフラストラクチャの保護
HYCU は、Google Cloudインフラストラクチャ、DBaaS、PaaS、およびSaaS全体で、自動バックアップときめ細かなリストアを提供します。実際、HYCUはGoogle Cloudインフラストラクチャとサービスを最も包括的にカバーしており、以下のサービスを完全にサポートしています:
- Google Cloud Engine (GCE)
- Google Cloud Storage
- Google CloudSQL
- Google BigQuery
- Google Kubernetes Engine (GKE)
- Google Cloud VMware Engine
- Google Workspace
- SAP HANA in Google Cloud
Protect multi-cloud infrastructure、PaaS、DBaaS、SaaSを保護
HYCUはBigQueryデータのバックアップにとどまりません;さまざまなデータソースやワークロードにも対応しています。つまり、Google、他のパブリッククラウド、オンプレミスのデータセンター、あるいはSaaS、DBaaS、PaaSアプリケーションに他のワークロードがある場合でも、HYCUはシームレスにバックアップと復元を行うことができます。
その一方で、BigQueryに特化して、HYCUは包括的なデータ保護を提供します。これにより、個々のテーブルやスキーマを含むすべてのBigQueryデータを確実にリストアできます。
💡 関連 → Top 14 SaaS Backup Solutions & Tools for SaaS Data Protection
Subscribe and protects in a few clicks
HYCUの際立った特徴の1つは、ユーザーフレンドリーなインターフェイスと徹底したドキュメントです、これにより、BigQueryバックアップの設定や構成が簡単になります。
たとえば、HYCUはアカウント内のすべてのインスタンスとワークロードを自動的に検出することで、バックアップ操作を簡素化します。
特筆すべきは、これらのポリシーは「セット・アンド・フォーゲット」であるということです。つまり、手動操作や日々の管理なしに、24時間365日稼働します。
データ保護とセキュリティの強化
Google Cloud IAM (Identity and Access Management)の役割と権限を自動的に継承するだけでなく、HYCUは役割ベースのアクセス制御(RBAC)機能も提供します。
この機能により、バックアップとリストア操作のアクセス権と役割を定義できます。
この統合により、バックアップとリストア操作が許可されたユーザーによってのみ実行されることが保証されます。
費用対効果の高い価格設定
HYCUは柔軟な価格設定オプションを提供しており、あらゆる規模の企業が堅牢なバックアップ機能の恩恵を受けられるようになっています。HYCUの利用コストは、バックアップが必要なデータ量、バックアップの頻度、必要な保存期間など、特定のニーズに合わせて調整できます。このアプローチにより、お客様の要件に合わせてサービスを調整することができ、必要な分だけお支払いいただくことができます。
保護ステータスで Google エステートを一望
一般的な組織であれば、他のパブリック クラウド サービスや SaaS アプリケーションとともに、より多くの Google サービスを使用していることでしょう。これは、データと構成が保護され、復元可能であることを確認することはおろか、追跡する上でも大きな課題となります。R-Graphを使用することで、HYCUユーザはすべてのクラウドインフラ、サービス、PaaS、DBaaS、SaaSを1つの「宝の地図」ビューで追跡することができます。どのサービスが保護され、コンプライアンスに準拠しているか、また、どのサービスの保護が必要かを追跡することができます。
関連 → Google Workspace (G Suite) Backup & Recovery Solution
Default BigQuery Backup Options and Configurations
BigQuery Backupを有効にするには、以下の管理者権限が必要です、データセットを管理するには、以下のIAMロールを持つ管理者アクセスが必要です:
- データセットのコピー(ベータ版):
- コピー先プロジェクトのBigQuery管理者(roles/bigquery.admin)
- コピー元データセットのBigQueryデータビューアー(roles/bigquery.dataViewer)
- コピー先データセットのBigQueryデータエディター(roles/bigquery.dataEditor)
- データセットの削除:プロジェクトのBigQueryデータ所有者(roles/bigquery.dataOwner)
- 削除したデータセットを復元します:
- 削除したデータセットを復元する:プロジェクトのBigQuery管理者(roles/bigquery.admin)
アクセス権を取得したら、以下のバックアップ設定とオプションを管理できます。
データセットレベルのコピーバックアップ
BigQueryにおける典型的なデータセットは、テーブルとビューを格納するトップレベルのコンテナです。また、データを整理し、データへのアクセスを制御する効果的な方法でもあります。たとえば、未加工データと処理済みデータを分けたり、異なる部署やプロジェクトのデータを分けたりすることができます。
一方、データセットレベルのバックアップを構成するには、データのコピーを作成し、特定の場所(クラウドストレージのバケットなど)にエクスポートします。
データセットレベルのバックアップを設定する方法
データセットレベルのバックアップを設定する方法には、BigQuery APIとSQLコマンドの2つがあります。
BigQuery APIを使用する
BigQuery APIを使用すると、BigQueryデータ転送サービスを使用して、クラウドストレージバケットに対するBigQueryからの自動データ転送をスケジュールできます。
- バックアップはGoogle Cloud Storageバケットに保存されるので、Cloud Consoleの「Storage」セクションに新しいバケットを作成します。
- APIライブラリに移動し、BigQueryデータ転送サービスAPIを有効にしますクラウドストレージAPI.
- プログラミング言語を選択し、BigQuery API用の対応するクライアントライブラリをインストールします。ドキュメントはこちら.
- GoogleクラウドSDKをインストールします。
- gCLIのコマンドを使用して、Google CloudアカウントでSDKを認証します。これにより、SDKがあなたに代わってアクセスし、操作を実行できるようになります。
- まだ持っていない場合は、新しいデータセットを作成します。
- データセット、プロジェクト、テーブルID、クラウドストレージバケットを指定します。
- APIにリクエストすることで、BigQueryテーブルからクラウドストレージバケットにデータをエクスポートします。
プロセスを確認したら、潜在的な問題を避けるために、BigQueryデータセットとCloud Storageが正確な場所にあることを確認します。
注意点 → このBigQueryバックアップオプションは、既存データのコピーのみであり、増分ではありません。
推奨
SQLコマンドの使用
BigQueryのSQLコマンドは、データセットを管理し、操作するための別のオプションを提供します。「データのバックアップ」というコンテキストでは、これは完全には不可能です。代わりに、既存のデータで新しいテーブルを作成します。
推奨→SQLコマンドを使ったデータセットの作成に関するGoogleのドキュメントをお読みください。
注意:これは正確には「バックアップ」ソリューションではありません。
BigQueryでこれらのバックアップ構成を設定する以外に、考慮する必要がある重要なパラメータがいくつかあります:
- バックアップの頻度。これはデータの変更頻度に完全に依存します。データが急速に変化する場合は、毎日または毎時のバックアップが必要かもしれません。そうでない場合は、毎月または毎週に設定できます。
- 保持ポリシー。これは全体で同じではなく、業界を管理するデータ法に準拠している限り、企業の要件に基づいて定義できます。
- スキーマの保存。構成のこの重要な側面は、データのスキーマ(または構造)が無傷のままであることを保証します。つまり、すべてのデータ型、名前、テーブル、およびその他の関連情報は、レプリケーション中でも正確です。
テーブルレベルのスナップショット
BigQueryのテーブルレベルのバックアップでは、データセット内の個々のテーブルを選択してバックアップすることができます。これは、データセット内の一部のテーブルのみバックアップが必要な場合に特に便利です。
個々のテーブルに対するスナップショットの作成。
- コマンドラインツールから'bq extract'コマンドを使用するか、
- BigQuery APIを使用してリクエストします。
以下に例を示します:
bq extract 'my_dataset.my_table' gs://my_bucket/my_table_backup
Where:
- 'my_dataset.my_table'はバックアップしたいテーブルで、
- 'gs://my_bucket/my_table_backup'はバックアップが保存されるGCSの場所です。
どちらの方法も、テーブルデータを選択した形式のファイルとしてGoogle Cloud Storage(GCS)バケットにエクスポートします。
GCSはセキュリティ、信頼性、費用対効果の点で、BigQueryテーブルバックアップの保存先として望ましい選択肢です。
BigQueryテーブルのバックアップをさまざまな形式でエクスポートします。
テーブルデータは以下の形式でエクスポートできます:
- JSON(Javascript Object Notation)。これは柔軟で人間が読みやすい形式なので、理解しやすく、作業も簡単です。
- CSV(カンマ区切り値)。これはシンプルで、ほとんどのテーブルデータ表現シナリオで広くサポートされているフォーマットです。
- Avro は行指向のデータシリアライズフレームワークです。そのコンパクトなバイナリフォーマットは、特にテーブルスキーマが時間とともに変化するような大規模なデータセットを扱うのに理想的です。
- Parquet (Apache Parquet)は列指向のデータストレージフォーマットです。大きなデータセットも扱うことができ、優れた圧縮機能を提供します。しかし、テーブルの頻繁な更新に関しては制限があるかもしれません。
パーティショニングされたBigQueryテーブルの処理と増分バックアップ
BigQueryにおけるテーブルのパーティショニングは、大規模なデータセットを管理および整理するためのアプローチです。
理想的には、既存のパーティション戦略に基づいてバックアップを実行すべきです。
そのためには、
- すべてのパーティションを含むテーブル全体をバックアップするか、または
- 特定のパーティションをバックアップします。
ただし、インクリメンタルバックアップを扱う場合、変更されたパーティションまたは新しく追加されたパーティションのみをエクスポートする方がストレージ効率は高くなります。
たとえば、テーブルが日付でパーティショニングされている場合、今日のパーティションのみを抽出できます。
テーブルレベルスナップショットの制限事項
- テーブルスナップショットは、そのベーステーブルと同じリージョンにあり、同じ組織の下になければなりません
- テーブルスナップショットは読み取り専用です。スナップショットから標準テーブルを作成し、データを更新しない限り、テーブルスナップショットのデータを更新することはできません。テーブルスナップショットのメタデータ(たとえば、説明、有効期限、アクセスポリシーなど)のみを更新できます。
- テーブルのデータのスナップショットを取得できるのは、タイムトラベルの7日間の制限により、7日前またはそれよりも最近のデータのみです。
- ビューまたはマテリアライズド・ビューのスナップショットを作成することはできません。
- 外部テーブルのスナップショットを作成することはできません。
- テーブル・スナップショットを作成するときに、既存のテーブルまたはテーブル・スナップショットを上書きすることはできません。
- 書き込み最適化ストレージ (ストリーミング バッファ) にデータがあるテーブルをスナップショットした場合、書き込み最適化ストレージ内のデータはテーブル スナップショットに含まれません。
- タイム トラベル内のデータがあるテーブルをスナップショットした場合、タイム トラベル内のデータはテーブル スナップショットに含まれません。
- パーティション有効期限が設定されているパーティション化テーブルをスナップショットした場合、パーティション有効期限情報はスナップショットに保持されません。'snapshotted'テーブルは、宛先データセットのデフォルトのパーティション有効期限を代わりに使用します。パーティション有効期限情報を保持するには、代わりにテーブルをコピーしてください。
- テーブルのスナップショットをコピーすることはできません。
スナップショットベースのバックアップ
BigQueryにおけるスナップショットは、テーブル(ベーステーブルと呼ばれます)のデータのポイントインタイムコピーです。つまり、特定の時点におけるテーブルとそのデータの状態をキャプチャし、必要に応じてその特定の時点からリストアできるようにします。
簡単に言えば、データの写真を撮るということです。また、コンプライアンス、監査、または傾向分析など、ある時点に存在したデータの一貫したビューを提供するような場合に価値があります。
💡注意 → テーブルスナップショットは「読み取り専用」ですが、スナップショットから標準テーブルを作成/復元し、それを変更することができます。
ポイントインタイムリカバリのためのスナップショットの作成と管理
以下のオプションを使用して、テーブルのスナップショットを作成できます:
- Googleクラウドコンソール
- SQLステートメント
bq cp --snapshotコマンド- jobs.insert API
たとえば、Googleクラウドコンソールを使用している場合は、次の手順に従います:
- Cloud Consoleに移動し、BigQueryページに移動します。
- 「エクスプローラー」ペインを見つけ、スナップショットしたいテーブルのプロジェクトノードとデータセットノードを展開します。
- テーブル名をクリックし、'スナップショット'をクリックします。

- 次に、'テーブルスナップショットの作成'が表示されます。新しいテーブルスナップショットのために、プロジェクト、テーブル、データセットの情報を入力します。
- 有効期限を設定します。
- 保存
このスナップショットを作成すると、元のテーブルから切り離されます。つまり、テーブルに変更を加えても、新しいテーブルのスナップショットのデータには影響しません。
推奨 → 他のオプションを使用したテーブルスナップショットの作成について詳しくはこちら
スナップショットベースのバックアップの利点
- データのバージョン管理。これにより、特定の時点でのデータにアクセスできます。
- 履歴分析
- データのバージョン管理
これにより、特定の時点のデータにアクセスできます。異なるスナップショットを比較して、時間の経過に伴うデータの変化を追跡できます。これにより、傾向を把握し、意思決定プロセスを改善することができます。
- データ保持。業界や組織によっては、規制要件に準拠するために厳格なデータ保持ポリシーを持っています。スナップショットベースのバックアップは、規制によって義務付けられている特定の期間、データを保持することを可能にします。
データ復元にBigQueryのタイムトラベル機能を利用する
BigQueryには「タイムトラベル」という機能があり、過去7日間のテーブルの履歴バージョンにアクセスすることができます。
タイムトラベル機能を使用すると、特定の時間からテーブルのデータを復元または保存し、選択したタイムスタンプ以降に行われた変更を元に戻すことができます。
スナップショットベースのバックアップとタイムトラベル機能は、BigQueryにおけるデータ保護戦略を大幅に強化します。
「タイムトラベル」は、運用障害、サイバー攻撃、または自然災害が発生した場合の復旧を保証するソリューションではないことに注意してください。
その理由は次のとおりです:
- データ復旧の期間は7日間に限られます。
- タイムトラベルは、データの複製やバックアップのオプションを提供しません。単にデータの以前の状態に戻ることができるだけです。
このため、包括的なデータの安全性を確保するには、Google Cloud Storageへの定期的なデータエクスポートやデータレプリケーションなど、他のバックアップ手段を採用することが重要になります。
BigQueryバックアップソリューションの実装
PythonとGitHubの使用
使いやすく膨大なライブラリをサポートするPythonを使用すると、BigQueryと簡単にやり取りでき、バックアッププロセス全体を自動化できます。
現在、Pythonと、コードをホスティングしバージョン管理するための主要なプラットフォームであるGitHubを使用することで、スクリプトを管理し、変更を追跡し、さらに他の人と共同作業することができます。
これを実現するには、既存のPythonライブラリとリポジトリを活用して開発プロセスを効率化する必要があります:
- google-cloud-bigquery.この公式 Python ライブラリは Google Cloud によるもので、データセットの管理、スケジューリング、クエリの実行などの機能を提供します。
Pythonを使ってクエリを実行する例を示します
from google.cloud import bigquery
client = bigquery.Client()
# クエリを実行します。
QUERY = (
'SELECT name FROM `bigquery-public-data.usa_names.usa_1910_2013` '
'WHERE state = "TX" '
'LIMIT 100')
query_job = client.query(QUERY) # APIリクエスト
rows = query_job.result() # クエリの終了を待ちます。
for rows:
print(row.name)- google-cloud-storage.
- pandas-gbq.このライブラリはBigQueryとPandasの橋渡しをします。
pandas-gbqライブラリでできることの例:
クエリを実行します:
import pandas_gbqresult_dataframe = pandas_gbq.read_gbq("SELECT column FROM dataset.table WHERE value = 'something'")
データフレームのアップロード:
pandas_gbqをインポートpandas_gbq.to_gbq(dataframe, "dataset.table")
さらに、PythonとGitHubを使ってBigQueryのバックアップを作成する際には、いくつかの標準的なベストプラクティスを守ることが重要です。
- バックアップジョブを監視します。エラー処理とロギングをスクリプトに実装して、バックアッププロセスで起こりうる問題を通知するアラートシステムをトリガーしましょう。
- Pythonスクリプトをモジュール化しましょう。モジュール化とは、単純に、プログラムが複雑になるのを整理する方法です。この場合、バックアップ関連の関数を再利用可能なモデルに分割することで、管理しやすくなり、成長しても保守しやすくなります。
- 設定ファイルを使用する。設定ファイル」とも呼ばれ、Pythonコードのキーと値のペアを保存するために使用されます。例えば、BigQueryのバックアップを実行する場合、設定ファイルを使用して、プロジェクトID、データセット名、バックアップ場所を保存することができます。これにより、コードに手を加えることなく簡単に変更できます。
コマンドラインとGoogle Cloud SDKの使用
コマンドライン(またはgCLI)は、Google Cloud上でホストされているアプリケーションとリソースを管理するために使用されるツールのセットです。これらのツールには、gcloud、gsutil、および bq コマンドライン ツールが含まれます。たとえば、バックアップ関連のすべてのタスクをコマンドラインでスケジュールし、自動化することができます。
一方、Google Cloud SDKを使用すると、お好みのプログラミング言語を使用してGoogle Cloud APIを簡単に開発および操作できます。
両方を組み合わせることで、BigQueryのバックアップを便利に管理できます。
GoogleクラウドSDKの設定方法。
- クラウドSDK - ライブラリとコマンドラインツール|Google Cloud にアクセスしてください。./google-cloud-sdk/install.sh'を使用してGoogle Cloud SDKをインストールし、必要なプロンプトに従います。
- 'gcloud auth login'コマンドラインを使用して、BigQueryリソースを有効にするためにアカウントを認証します。
これでGoogle Cloud SDKがセットアップされたので、次はコマンドラインを使ってさまざまなバックアップ機能を実行します。
バックアップの作成
'[bq cp]'コマンドラインを使用してBigQueryバックアップを作成するには、単にテーブルをある場所から別の場所にコピーします。その場所は、異なるプロジェクト、異なるデータセット、あるいは同じデータセット内であってもかまいません。
bq cp [project_id]:[dataset].[table] [project_id]:[backup_dataset].[backup_table]
Where your;
- '[project_id]'はGoogle Cloud IDです。
- '[dataset]'にはバックアップしたいテーブルが含まれています。
- '[table]'にはバックアップしたいテーブルの名前が入ります。
- '[backup_dataset]'はバックアップを保存したいデータセットです。
- '[backup_table]'はバックアップテーブルの名前です。
データのエクスポート
BigQueryからGoogle Cloud Storageや外部ストレージシステムにデータをエクスポートするには、'[bq extract]'コマンドラインを使用します。このコマンドラインでは、JSON、CSV、Avro、Parquetでのデータエクスポートも可能です。
bq extract --destination_format=[format] [project_id]:[dataset].[table] gs://[bucket]/[path]
ここで、
- '[format]'を希望のエクスポート形式に置き換えてください。
- '[bucket]'には、Google Cloud Storageのバケット名を指定します。
- '[path]'には、エクスポートしたデータを保存するパスを指定します。
例えば:
bq extract --destination_format CSV 'mydataset.mytable' gs://mybucket/mydata.csv
バックアップの管理
BigQueryのバックアップを管理するには、'[bq ls]'コマンドを使用して、特定のデータセット内のすべてのバックアップ(またはテーブル)を一覧表示します。
bq ls mydatasetbq rm 'mydataset.mytable'
BigQuery バックアップ オプションの制限事項
ポイントインタイム リカバリ オプションの制限事項
頻繁に更新や変換が行われる重要なデータセットがBigQueryにあるとします。ある日、データ破損の問題によりデータセットが不正確になりました。
BigQueryはポイントインタイムリカバリを提供していないため、データセットを破損が発生する前の状態に簡単に復元することはできません。
複雑なインポートおよびエクスポートプロセス
BigQueryに大規模なデータセットがあり、Google Cloud Storage(GCS)などの外部ストレージシステムにバックアップを作成したいとします。BigQueryではAvro、Parquet、CSVなどの形式でデータをエクスポートできますが、大規模なデータセットのエクスポートは複雑でリソースを消費します。
たとえば、数テラバイトのデータをGCSにエクスポートする場合、かなりの時間とネットワークリソースが必要になり、追加コストと継続的な運用の中断につながる可能性があります。
劣悪なバックアップ保持ポリシー
デフォルトでは、BigQueryは削除されたテーブルまたはデータセットを永久削除する前に30日間「ゴミ箱」に保持します。
リソースを必要とするスクリプトと構成
スクリプトとカスタム構成の管理は、特に環境の規模が大きくなるにつれて複雑になる可能性があります。スクリプトの管理は、BigQueryのようなサービスはもちろんのこと、複数のクラウドサービスの管理を担当している場合にも、大変な労力と時間がかかります。
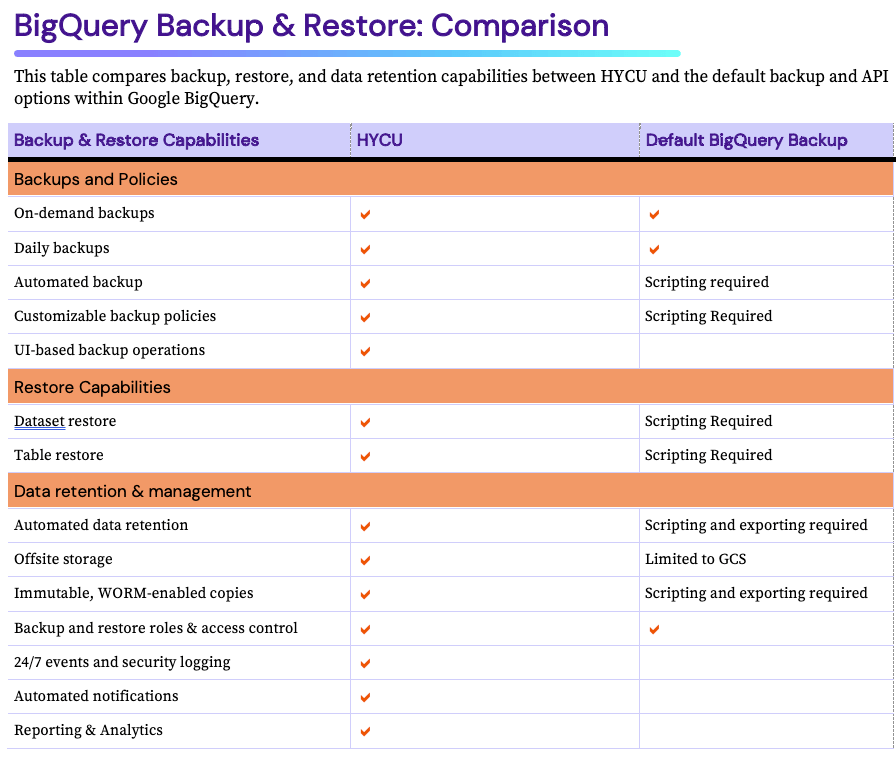
BigQuery バックアップとリカバリ:結論
Google BigQueryは、データ駆動型の組織にとって間違いなく強力なツールです。非常に高速なSQLクエリ、組み込みの機械学習機能、スケーラブルなインフラストラクチャにより、特に大量のデータを処理するための信頼性の高いソリューションとなっています。しかし、BigQueryに存在する貴重なスキーム、データセット、テーブルは、データ損失やシステム障害のリスクを軽減するために保護する必要があります。そこでHYCUが登場します。
HYCU Protégéを使用すると、BigQueryデータを1クリックでバックアップし、きめ細かくリストアできます。この自動化された「セット・アンド・フェザー」バックアップは、24時間365日稼働し、必要なときにBigQueryデータを利用できるという安心感を提供します。
。



最新の知見や最新情報を入手しましょう
By submitting, I agree to the HYCU Subscription Agreement , Terms of Usage , and Privacy Policy .